
В этом очерке я опишу свое видение двух схожих моделей в бизнес-анализе — модели предметной области (aka бизнес-домена) и логической модели данных. Первая вполне может породить со временем вторую, а обе они — основные структурные визуальные модели, иметь которые в кармашке полезно каждому уважающему себя аналитику.
Надо бы пояснить, что я приверженец разграничения терминов «модель» и «диаграмма» в ряде ситуаций. Модель — это что-то, что является задачей БА; то, что БА ради какой-то видимой пользы строит. Диаграмма — инструмент, с помощью которого можно эти самые модели строить. Термины можно подобрать и иные, но поясню на примере: есть чудесная нотация моделирования UML, и вот там как раз фигурируют «диаграммы» (Use Case Diagram, Activity Diagram и т. д.). И если с Use Case Diagram все более-менее однозначно (нет множественности вариаций применения — большинству понятно, зачем вы будете эту диаграмму использовать; хотя есть подходы, где юз кейсики делятся на бизнес- и системные, и, соответственно, можно строить две разные смысловые модели с помощью одного инструмента), то вот, например, а как будет стоять постановка задачи с рисованием Activity Diagram или Class Diagram? Каждому бойцу в ногу с объёмом знаний/незнаний в области БА и в меру извращенности фантазии придёт в голову свое, когда он решит построить диаграмму классов, увидев в этих ваших интернетах, что для БА это полезно. Особенно фанатичные аналитики примутся даже вычерчивать структуру классов программного кода, нацелившись стать героями посмертно. Поэтому что действительно полезно понимать касательно диаграммы классов в UML и прочих диаграмм в прочих нотациях, так это то, что это отличный молоток, которым можно и нужно забивать правильные гвозди. Соответственно, для БА нужные гвозди в контексте сабжа — те самые две упомянутые в начале статьи модели. Причём диаграмма классов UML — это не единственный подходящий молоточек: есть ещё ERD со своими вариациями нотаций, IDEF0 и ряд других менее известных нотаций и видов диаграмм в них. Но мы будем изучать сабжевые модели именно в преломлении UML Class Diagram, т. к. к этой нотации я питаю теплые чувства. Но давайте к делу.
Экспозиция. Вы только что стартовали новый проект и активно мучаете заказчика, дабы понять, что он там себе надумал в качестве очередной идеи по порабощению мира. Пыхтя и сопя, вы с боем вычленяете крупицы видения и требований к будущему решению, продираясь через горы неизвестных вам бизнес-терминов, правил, политик работы и пр. Давайте оживим пример. Пусть это будет что-то, дорогое сердцу большинства геймеров и не только, — представим, что заказчик решил сделать сайт-путеводитель по чудесному миру Ведьмака Анджея Сапковского и нацелился генерить бабосики на премиум-подписках (оставим, правда, это за рамками моделей в статье, дабы не усложнять). Допустим, вы примерно уяснили, для кого это все и на кой это все, и решили погрузиться в этот чудесный мир с головой, чтобы не просто служить набивателем контента, а понимать досконально, что и зачем клиент будет пихать в свой путеводитель и быть в состоянии активно помогать и советовать. То бишь на каком-то этапе проекта вам с разной степенью погружения (зависит от суровости проекта, вовлеченности команды и прочих нюансов) нужно так или иначе заняться изучением предметной области (или бизнес-домена, или просто домена). Наш любимый BABOK гласит, что домен — это сфера знаний, определяющая множество общих требований, терминологию и функциональность программы или инициативы, решающей некоторую задачу. Ну… они пытались. Переведу: некая область знаний, которая имеет непосредственное отношение к Изменению (вспоминаем модель базовых понятий в BABOK), определяемая общим информационным наполнением, терминологией и всяким прочим общим. В нашем примере — это мир Ведьмака. В вашем проекте это может быть страхование в Республике Беларусь, здравоохранение в Зимбабве, заказ еды в Интернете и прочие области, которые определяют бизнес-сторону вашего проекта (деятельность заказчика или конечных пользователей).
В общем, вы решили погрузиться в домен, то бишь понять, что за мир наваял там для нас пан Сапковский, чтобы потом уже с чувством и с толком участвовать в генерации идей вместе с заказчиком. Что вам нужно сделать? Очевидно, изучить все имеющиеся источники и, в первую очередь, — первоисточники. Нет, можно, конечно, пойти к заказчику и попросить его рассказать сказку на ночь, но как-то это не огонь. Я бы на месте такого клиента вежливо или не очень уточнил, почему вам не позволяет религия изучить сперва все имеющиеся материалы, чтобы потом только обсудить что-то, что вы не поняли. Соответственно, вы ныряете в книжки, а затем — в игры, и даже сериал вечерком посматриваете, плюясь и ругаясь на то, как бездарно его создатели обошлись с материалом. И главный челлендж тут — законспектировать (назовем это так) получаемые знания. Вам нужно эти самые знания структурировать и упорядочить, убрав всю левую шелуху и связав все в единую красивую картину. Поверьте, после изучения всех упомянутых источников информации у вас будет выше крыши, и если вы нацелены на то, что получение информации аналитиком в таком аспекте — это просто изучить, а потом оперировать тем, что волей случая осело в голове, то пора поговорить о вашей квалификации. У вас должен быть некий структурированный дистиллят всего того, что вы черпанули из кучи источников (пусть будет конспект как упрощенный термин). Давайте абстрагируемся от нашего примера: вы применили весь ваш арсенал техник извлечения информации — побеседовали с массой заинтересованных лиц, изучили кучу талмудов и статей в сети, даже наблюдение какое-то провели и пр. — есть итоговый набор знаний о предметной области. Как он представлен? Набор хаотичных заметок? Ну и на кой они вам по итогу? Захотите вы отыскать ответ на интересующий вас вопрос — будете искать в десятках противоречащих друг другу кусков текста, параллельно делая очередной анализ? Думаю, понятно, что лучше упорядочить все это дело, дабы это было юзабельным в дальнейшем. И не считая варианта просто все это дело представить в текстовом, но уже ограненном и разбитым на структурные элементы виде, я фанат двух подходов в такой ситуации:
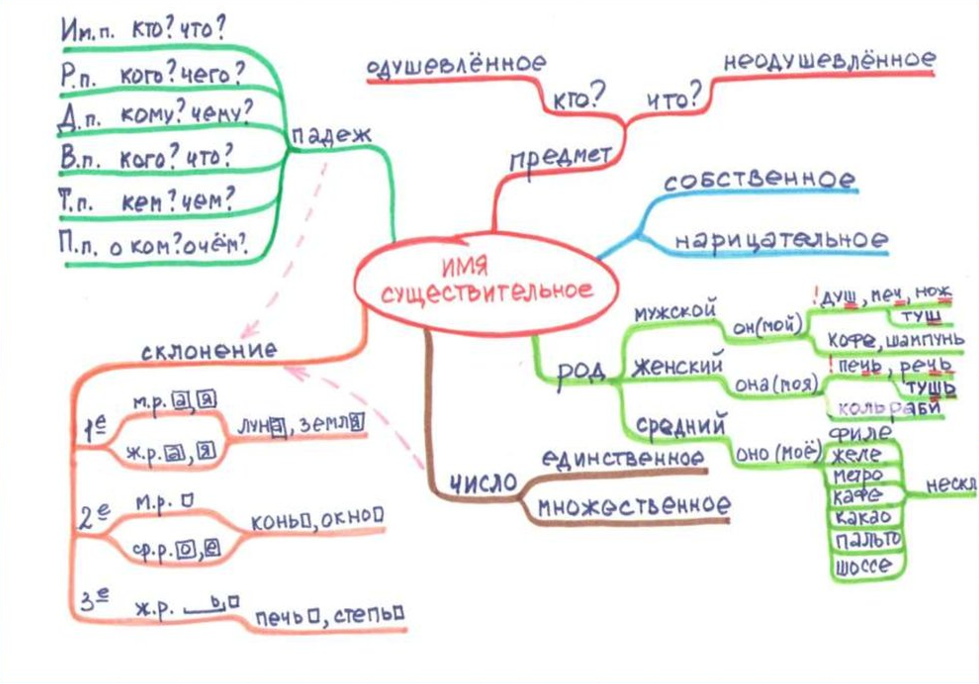
1) Ментальные карты (mind maps). Простой, но крайне мощный в плане применимости механизм представления информации в древовидном виде. Применение простое: вы изучаете информацию и конспектируете ключевые вещи в виде дерева, где каждый очередной уровень веток — это следующий уровень информации. При этом вы сравниваете получаемую вами информацию с тем, что вы наконспектировали ранее, дополняя или изменяя предыдущее. Все вот так просто — немного набить руку и перед вами мощнейший инструмент составления упорядоченных заметок для любого рода информации, с которой вы работаете:
Надо бы пояснить, что я приверженец разграничения терминов «модель» и «диаграмма» в ряде ситуаций. Модель — это что-то, что является задачей БА; то, что БА ради какой-то видимой пользы строит. Диаграмма — инструмент, с помощью которого можно эти самые модели строить. Термины можно подобрать и иные, но поясню на примере: есть чудесная нотация моделирования UML, и вот там как раз фигурируют «диаграммы» (Use Case Diagram, Activity Diagram и т. д.). И если с Use Case Diagram все более-менее однозначно (нет множественности вариаций применения — большинству понятно, зачем вы будете эту диаграмму использовать; хотя есть подходы, где юз кейсики делятся на бизнес- и системные, и, соответственно, можно строить две разные смысловые модели с помощью одного инструмента), то вот, например, а как будет стоять постановка задачи с рисованием Activity Diagram или Class Diagram? Каждому бойцу в ногу с объёмом знаний/незнаний в области БА и в меру извращенности фантазии придёт в голову свое, когда он решит построить диаграмму классов, увидев в этих ваших интернетах, что для БА это полезно. Особенно фанатичные аналитики примутся даже вычерчивать структуру классов программного кода, нацелившись стать героями посмертно. Поэтому что действительно полезно понимать касательно диаграммы классов в UML и прочих диаграмм в прочих нотациях, так это то, что это отличный молоток, которым можно и нужно забивать правильные гвозди. Соответственно, для БА нужные гвозди в контексте сабжа — те самые две упомянутые в начале статьи модели. Причём диаграмма классов UML — это не единственный подходящий молоточек: есть ещё ERD со своими вариациями нотаций, IDEF0 и ряд других менее известных нотаций и видов диаграмм в них. Но мы будем изучать сабжевые модели именно в преломлении UML Class Diagram, т. к. к этой нотации я питаю теплые чувства. Но давайте к делу.
Экспозиция. Вы только что стартовали новый проект и активно мучаете заказчика, дабы понять, что он там себе надумал в качестве очередной идеи по порабощению мира. Пыхтя и сопя, вы с боем вычленяете крупицы видения и требований к будущему решению, продираясь через горы неизвестных вам бизнес-терминов, правил, политик работы и пр. Давайте оживим пример. Пусть это будет что-то, дорогое сердцу большинства геймеров и не только, — представим, что заказчик решил сделать сайт-путеводитель по чудесному миру Ведьмака Анджея Сапковского и нацелился генерить бабосики на премиум-подписках (оставим, правда, это за рамками моделей в статье, дабы не усложнять). Допустим, вы примерно уяснили, для кого это все и на кой это все, и решили погрузиться в этот чудесный мир с головой, чтобы не просто служить набивателем контента, а понимать досконально, что и зачем клиент будет пихать в свой путеводитель и быть в состоянии активно помогать и советовать. То бишь на каком-то этапе проекта вам с разной степенью погружения (зависит от суровости проекта, вовлеченности команды и прочих нюансов) нужно так или иначе заняться изучением предметной области (или бизнес-домена, или просто домена). Наш любимый BABOK гласит, что домен — это сфера знаний, определяющая множество общих требований, терминологию и функциональность программы или инициативы, решающей некоторую задачу. Ну… они пытались. Переведу: некая область знаний, которая имеет непосредственное отношение к Изменению (вспоминаем модель базовых понятий в BABOK), определяемая общим информационным наполнением, терминологией и всяким прочим общим. В нашем примере — это мир Ведьмака. В вашем проекте это может быть страхование в Республике Беларусь, здравоохранение в Зимбабве, заказ еды в Интернете и прочие области, которые определяют бизнес-сторону вашего проекта (деятельность заказчика или конечных пользователей).
В общем, вы решили погрузиться в домен, то бишь понять, что за мир наваял там для нас пан Сапковский, чтобы потом уже с чувством и с толком участвовать в генерации идей вместе с заказчиком. Что вам нужно сделать? Очевидно, изучить все имеющиеся источники и, в первую очередь, — первоисточники. Нет, можно, конечно, пойти к заказчику и попросить его рассказать сказку на ночь, но как-то это не огонь. Я бы на месте такого клиента вежливо или не очень уточнил, почему вам не позволяет религия изучить сперва все имеющиеся материалы, чтобы потом только обсудить что-то, что вы не поняли. Соответственно, вы ныряете в книжки, а затем — в игры, и даже сериал вечерком посматриваете, плюясь и ругаясь на то, как бездарно его создатели обошлись с материалом. И главный челлендж тут — законспектировать (назовем это так) получаемые знания. Вам нужно эти самые знания структурировать и упорядочить, убрав всю левую шелуху и связав все в единую красивую картину. Поверьте, после изучения всех упомянутых источников информации у вас будет выше крыши, и если вы нацелены на то, что получение информации аналитиком в таком аспекте — это просто изучить, а потом оперировать тем, что волей случая осело в голове, то пора поговорить о вашей квалификации. У вас должен быть некий структурированный дистиллят всего того, что вы черпанули из кучи источников (пусть будет конспект как упрощенный термин). Давайте абстрагируемся от нашего примера: вы применили весь ваш арсенал техник извлечения информации — побеседовали с массой заинтересованных лиц, изучили кучу талмудов и статей в сети, даже наблюдение какое-то провели и пр. — есть итоговый набор знаний о предметной области. Как он представлен? Набор хаотичных заметок? Ну и на кой они вам по итогу? Захотите вы отыскать ответ на интересующий вас вопрос — будете искать в десятках противоречащих друг другу кусков текста, параллельно делая очередной анализ? Думаю, понятно, что лучше упорядочить все это дело, дабы это было юзабельным в дальнейшем. И не считая варианта просто все это дело представить в текстовом, но уже ограненном и разбитым на структурные элементы виде, я фанат двух подходов в такой ситуации:
1) Ментальные карты (mind maps). Простой, но крайне мощный в плане применимости механизм представления информации в древовидном виде. Применение простое: вы изучаете информацию и конспектируете ключевые вещи в виде дерева, где каждый очередной уровень веток — это следующий уровень информации. При этом вы сравниваете получаемую вами информацию с тем, что вы наконспектировали ранее, дополняя или изменяя предыдущее. Все вот так просто — немного набить руку и перед вами мощнейший инструмент составления упорядоченных заметок для любого рода информации, с которой вы работаете:
2) Модель предметной области. Что сие есть? Это визуальная модель (схема, диаграмма), которая показывает всякими квадратиками и стрелочками ключевые понятия в предметной области (ее субъекты, объекты, термины и пр.) и то, как они между собой связаны. Она показывает структуру предметной области.
Как это строить? Изучая имеющийся у вас набор информации, вы выделяете ключевые существительные (понятия, объекты, субъекты — будем их далее называть сущностями предметной области) и помещаете их на диаграмму в виде элементов (классов, если мы говорим про UML Class Diagram). Затем вы выделяете глаголы — действия, процессы, события, отношения — и связываете с их помощью эти элементы на диаграмме (а это будем называть отношениями или связями между сущностями). Фактически, в базовом варианте это все.
Давайте на простом примере, с которого мы начали выше. Допустим, вы начали свое погружение в лор с изучения обзорных статей в Интернете. Описательный кусок взят отсюда:
Главным героем серии является Геральт из Ривии, ведьмак — истребитель чудовищ, угрожающих людям. Ещё ребёнком его отдали ведьмакам, которые забрали Геральта в старую крепость Каэр Морхен, где подвергли мутации, повысившей скорость его реакций, выносливость, сопротивляемость ядам и болезням. Он известен под несколькими прозвищами: Gwynbleidd — “Белый Волк” на Старшем наречии, Белоголовый ведьмак, а также Блавикенский Мясник.
Основная работа Геральта из Ривии — за деньги уничтожать опасных чудовищ и монстров. Этим ведьмак занимался долгое время, пока в его жизни не появилось нечто действительно важное: маленькая девочка по имени Цирилла. Но в результате интриг королей и магов ведьмак оказывается втянут в эпицентр противостояния Северных королевств и могущественной южной империи Нильфгаард. Геральт пытается спасти от тех и других юную Цири, княжну уничтоженного нильфгаардцами королевства Цинтра.
Каждая фракция, будь то правители нордлингов, император Нильфгаарда или Капитул чародеев, имеет собственные планы на Цири. Ведьмаку это совсем не нравится. Он готов защищать девочку единственно известным ему способом — убийством её недоброжелателей. Ко всему прочему Геральт пытается разобраться в своих неоднозначных отношениях с чародейкой Йеннифэр. Робкие чувства этих двоих могут не выжить, когда на арену выходят пресловутые “государственные интересы” и “высшие цели”.
Это и так достаточно сухой концентрат информации, но давайте попробуем представить это в виде модели, применив подход, который я описал выше. Я не буду описывать побуквенно полет мысли, который трансформировал текст выше в модель, но предлагаю вам погрузиться в это, читая текст и сверяя каждое его предложение с тем, как это отражено на рисунке.
Как это строить? Изучая имеющийся у вас набор информации, вы выделяете ключевые существительные (понятия, объекты, субъекты — будем их далее называть сущностями предметной области) и помещаете их на диаграмму в виде элементов (классов, если мы говорим про UML Class Diagram). Затем вы выделяете глаголы — действия, процессы, события, отношения — и связываете с их помощью эти элементы на диаграмме (а это будем называть отношениями или связями между сущностями). Фактически, в базовом варианте это все.
Давайте на простом примере, с которого мы начали выше. Допустим, вы начали свое погружение в лор с изучения обзорных статей в Интернете. Описательный кусок взят отсюда:
Главным героем серии является Геральт из Ривии, ведьмак — истребитель чудовищ, угрожающих людям. Ещё ребёнком его отдали ведьмакам, которые забрали Геральта в старую крепость Каэр Морхен, где подвергли мутации, повысившей скорость его реакций, выносливость, сопротивляемость ядам и болезням. Он известен под несколькими прозвищами: Gwynbleidd — “Белый Волк” на Старшем наречии, Белоголовый ведьмак, а также Блавикенский Мясник.
Основная работа Геральта из Ривии — за деньги уничтожать опасных чудовищ и монстров. Этим ведьмак занимался долгое время, пока в его жизни не появилось нечто действительно важное: маленькая девочка по имени Цирилла. Но в результате интриг королей и магов ведьмак оказывается втянут в эпицентр противостояния Северных королевств и могущественной южной империи Нильфгаард. Геральт пытается спасти от тех и других юную Цири, княжну уничтоженного нильфгаардцами королевства Цинтра.
Каждая фракция, будь то правители нордлингов, император Нильфгаарда или Капитул чародеев, имеет собственные планы на Цири. Ведьмаку это совсем не нравится. Он готов защищать девочку единственно известным ему способом — убийством её недоброжелателей. Ко всему прочему Геральт пытается разобраться в своих неоднозначных отношениях с чародейкой Йеннифэр. Робкие чувства этих двоих могут не выжить, когда на арену выходят пресловутые “государственные интересы” и “высшие цели”.
Это и так достаточно сухой концентрат информации, но давайте попробуем представить это в виде модели, применив подход, который я описал выше. Я не буду описывать побуквенно полет мысли, который трансформировал текст выше в модель, но предлагаю вам погрузиться в это, читая текст и сверяя каждое его предложение с тем, как это отражено на рисунке.
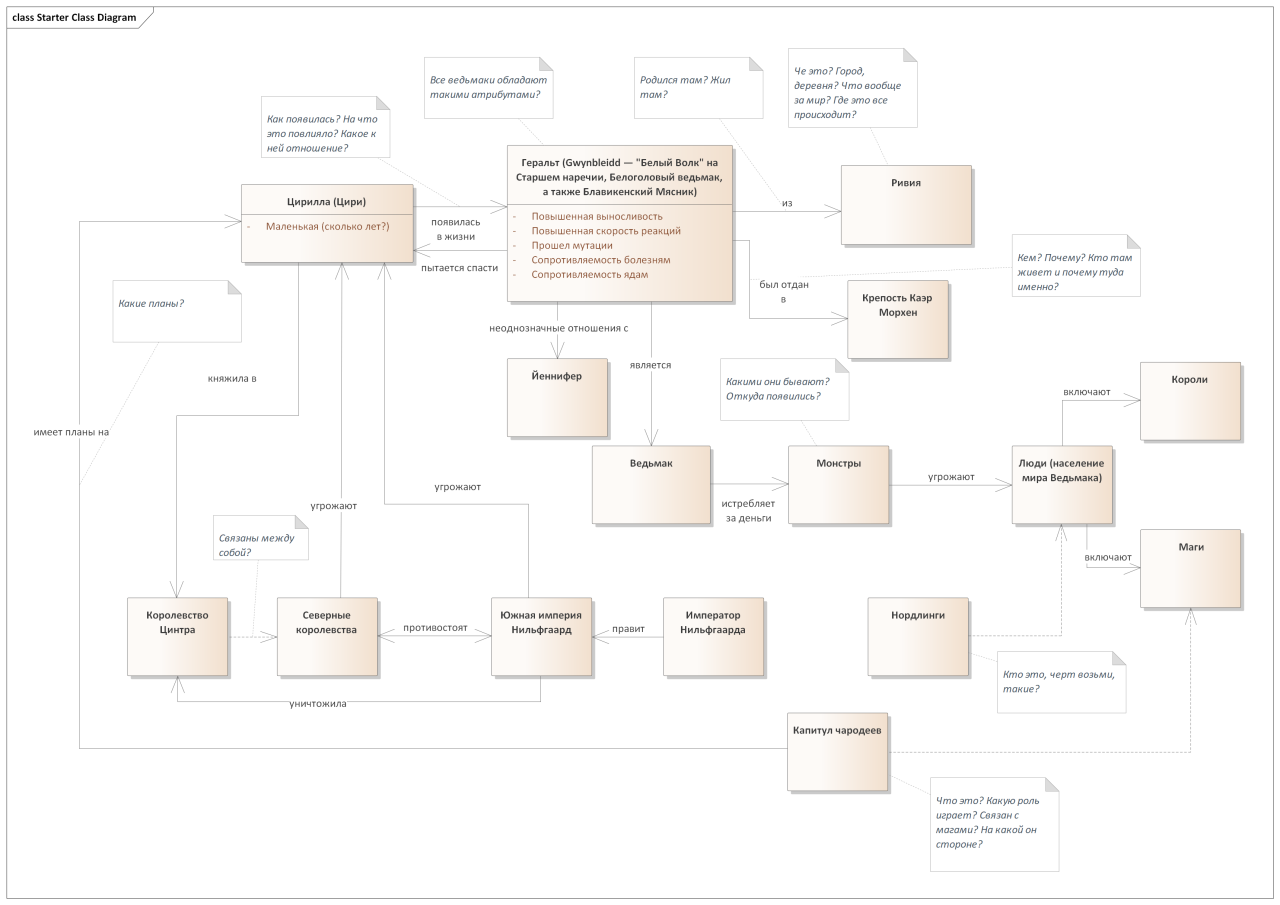
Наверняка видно, что по ходу вырисовывания я также добавлял заметки — некоторые из вопросов, которые возникали бы у меня, читай я этот текст впервые и не будучи знаком с предметной областью. И тут всплывает первая и важнейшая полезность применения модели — помощь БА в анализе информации. Я уверен, что просто прочитав исходный текст, я бы сходу не выписал себе ряд подобных (и потенциально жизненно важных) вопросов, которые надо так или иначе прояснить. Далее вы увидите ряд более сложных аспектов этой модели, которые помогут в анализе еще больше.
Что может помочь в продвинутом моделировании такого плана:
1) Всякие более навороченные связи/отношения, помимо банальной стрелочки (которая в UML, кстати, зовется ассоциацией). UMLпредоставляет три полезных для аналитика связи, которые имеют более специфичное, нежели универсально применимая ассоциация, значение:
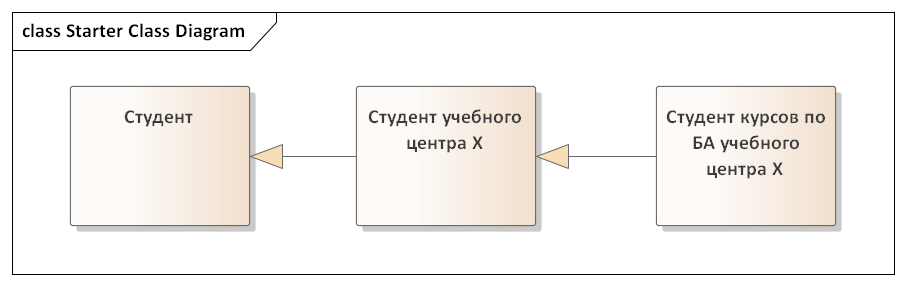
- Обобщение или наследование. Это связь между двумя элементами, которая показывает, что наследник — это дальнейшее уточнение родителя, т. е. элемента, от которого идет наследование. Иными словами, наследник — это то же самое, что и родитель, но со своими спецификами. Изображается сплошной линией с пустым треугольником на конце. Допустим, есть у нас класс Студент учебного центра X. Студент учебного центра X — это Студент, но мы добавили новый уточняющий параметр — студент какого-то учебного центра. Между Студентом и Студентом учебного центра X можно поставить связь обобщения. Мы можем и далее продолжить цепочку: Студент учебного центра X — Студент курсов по БА в учебном центре X. Т. е. по мере продвижения вглубь мы делаем классы все менее и менее абстрактными.
Кстати, наследование подразумевает, что класс-наследник перенимает все свойства (атрибуты, в частности) класса-родителя, но при этом, как правило, добавляет что-то свое, потому он и наследник.
Что может помочь в продвинутом моделировании такого плана:
1) Всякие более навороченные связи/отношения, помимо банальной стрелочки (которая в UML, кстати, зовется ассоциацией). UMLпредоставляет три полезных для аналитика связи, которые имеют более специфичное, нежели универсально применимая ассоциация, значение:
- Обобщение или наследование. Это связь между двумя элементами, которая показывает, что наследник — это дальнейшее уточнение родителя, т. е. элемента, от которого идет наследование. Иными словами, наследник — это то же самое, что и родитель, но со своими спецификами. Изображается сплошной линией с пустым треугольником на конце. Допустим, есть у нас класс Студент учебного центра X. Студент учебного центра X — это Студент, но мы добавили новый уточняющий параметр — студент какого-то учебного центра. Между Студентом и Студентом учебного центра X можно поставить связь обобщения. Мы можем и далее продолжить цепочку: Студент учебного центра X — Студент курсов по БА в учебном центре X. Т. е. по мере продвижения вглубь мы делаем классы все менее и менее абстрактными.
Кстати, наследование подразумевает, что класс-наследник перенимает все свойства (атрибуты, в частности) класса-родителя, но при этом, как правило, добавляет что-то свое, потому он и наследник.
- Агрегация и композиция. Обе эти связи показывают отношение «часть-целое». Т. е., простым языком, включение одного элемента в другой. Если композиция или агрегация идет от А к Б, это означает, что А является составной частью целого Б.
В чем разница между этими двумя связями? Агрегация изображается сплошной линией с незакрашенным ромбом на конце, а композиция — с закрашенным. Но, внезапно, это не вся разница. Агрегация считается слабой связью, а композиция — сильной. Если, в случае концептуального разрушения объекта-родителя, дочерние объекты также, образно или буквально, разрушаются (тут может быть физическое разрушение, расформирование, архивирование — все, что имеет оттенок разрушения в домене), то связь — сильная. Если дочерние объекты продолжают существовать, то связь — слабая.
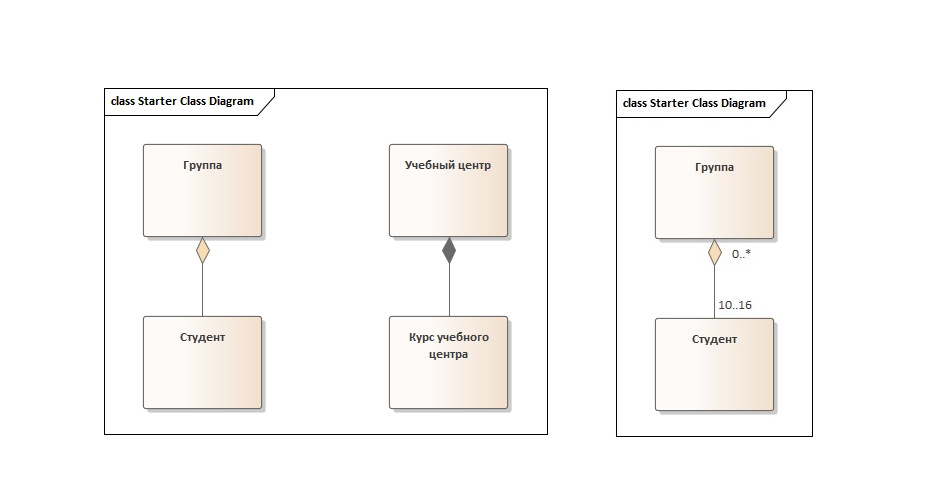
Давайте с примерами. Что такое агрегация? Наверняка вы слышали такое понятие, как каталоги-агрегаторы. Это нечто, что собирает информацию из разных мест в одну систему, но при этом не является владельцем этих вещей. Т. е. каталог-агрегатор — это такая система, которая при разрушении не приводит к разрушению тех компонентов, которые она собрала в себе, агрегировала. Все эти компоненты самостоятельны и живут и вне этой системы. Пример: Студент-Группа. Если представить себе, что Студент некоего учебного центра может одновременно посещать и Курс по бизнес-анализу, и Курс по базам данных, то вопрос: при расформировании группы Курса по бизнес-анализу теряют ли смысл, уничтожаются ли как объекты все ее Студенты? Нет, Студентом учебного центра человек остается, и он все еще может быть частью группы по базам данных, а может и не быть частью никакой группы — просто быть в базе учебного центра как прошлый или будущий Студент. Поэтому эта связь слабая.
Теперь, что такое композиция? Композиция — это когда составные части системы являются ее неотъемлемой частью и без системы смысла не имеют. Например, Курс учебного центра X — Учебный центр X. Если учебный центр, расформируется, такого понятия как Курс учебного центра не станет. Все курсы также концептуально уничтожатся. Это и есть сильная связь. Примеры см. на картинке ниже.
В чем разница между этими двумя связями? Агрегация изображается сплошной линией с незакрашенным ромбом на конце, а композиция — с закрашенным. Но, внезапно, это не вся разница. Агрегация считается слабой связью, а композиция — сильной. Если, в случае концептуального разрушения объекта-родителя, дочерние объекты также, образно или буквально, разрушаются (тут может быть физическое разрушение, расформирование, архивирование — все, что имеет оттенок разрушения в домене), то связь — сильная. Если дочерние объекты продолжают существовать, то связь — слабая.
Давайте с примерами. Что такое агрегация? Наверняка вы слышали такое понятие, как каталоги-агрегаторы. Это нечто, что собирает информацию из разных мест в одну систему, но при этом не является владельцем этих вещей. Т. е. каталог-агрегатор — это такая система, которая при разрушении не приводит к разрушению тех компонентов, которые она собрала в себе, агрегировала. Все эти компоненты самостоятельны и живут и вне этой системы. Пример: Студент-Группа. Если представить себе, что Студент некоего учебного центра может одновременно посещать и Курс по бизнес-анализу, и Курс по базам данных, то вопрос: при расформировании группы Курса по бизнес-анализу теряют ли смысл, уничтожаются ли как объекты все ее Студенты? Нет, Студентом учебного центра человек остается, и он все еще может быть частью группы по базам данных, а может и не быть частью никакой группы — просто быть в базе учебного центра как прошлый или будущий Студент. Поэтому эта связь слабая.
Теперь, что такое композиция? Композиция — это когда составные части системы являются ее неотъемлемой частью и без системы смысла не имеют. Например, Курс учебного центра X — Учебный центр X. Если учебный центр, расформируется, такого понятия как Курс учебного центра не станет. Все курсы также концептуально уничтожатся. Это и есть сильная связь. Примеры см. на картинке ниже.
2) Множественности на связях, уточняющие характер связей. Множественность связи показывает, какое количество объектов, экземпляров класса может присутствовать на концах связи.
Возьмем пример Студент — Группа, с агрегацией между ними, и на обеих концах этой самой агрегации определим множественность. Какие вопросы стоит для этой цели задавать? Для множественности рядом с классом Студент: какое количество Студентов может «тут подставляем название связи» (у нас это «входит в») одну Группу. Ответ (представим, что оно так) — от 10 до 16.
Теперь, что касается множественности около класса Группа. Вопрос похожий, но в обратную сторону. В каком количестве Групп может участвовать один Студент? Мы инвертировали название связи. Ответ: либо ни в одной (и да, он все еще будет Студентом — например, если он записался на обучение, которое не подразумевает нахождение в группе — именно поэтому у нас агрегация, а не композиция), либо в бесконечном числе (с неизвестным нам верхним ограничением), что обозначается звездочкой.
Возьмем пример Студент — Группа, с агрегацией между ними, и на обеих концах этой самой агрегации определим множественность. Какие вопросы стоит для этой цели задавать? Для множественности рядом с классом Студент: какое количество Студентов может «тут подставляем название связи» (у нас это «входит в») одну Группу. Ответ (представим, что оно так) — от 10 до 16.
Теперь, что касается множественности около класса Группа. Вопрос похожий, но в обратную сторону. В каком количестве Групп может участвовать один Студент? Мы инвертировали название связи. Ответ: либо ни в одной (и да, он все еще будет Студентом — например, если он записался на обучение, которое не подразумевает нахождение в группе — именно поэтому у нас агрегация, а не композиция), либо в бесконечном числе (с неизвестным нам верхним ограничением), что обозначается звездочкой.
3) Группировка элементов по тематическим областям или разнесение по разным диаграммам для сокращения вырвиглазности и улучшения читаемости. Тут, полагаю, очевидно.
Давайте попробуем применить эти самые дополнительные фишечки к предыдущей модели. Я уберу старые вопросы (полагая, что мы нашли на них ответ или же просто себе зафиксировали — чего им теперь перегружать диаграмму?) и добавлю ряд новых, на которые натолкнули новые аспекты модели.
Давайте попробуем применить эти самые дополнительные фишечки к предыдущей модели. Я уберу старые вопросы (полагая, что мы нашли на них ответ или же просто себе зафиксировали — чего им теперь перегружать диаграмму?) и добавлю ряд новых, на которые натолкнули новые аспекты модели.
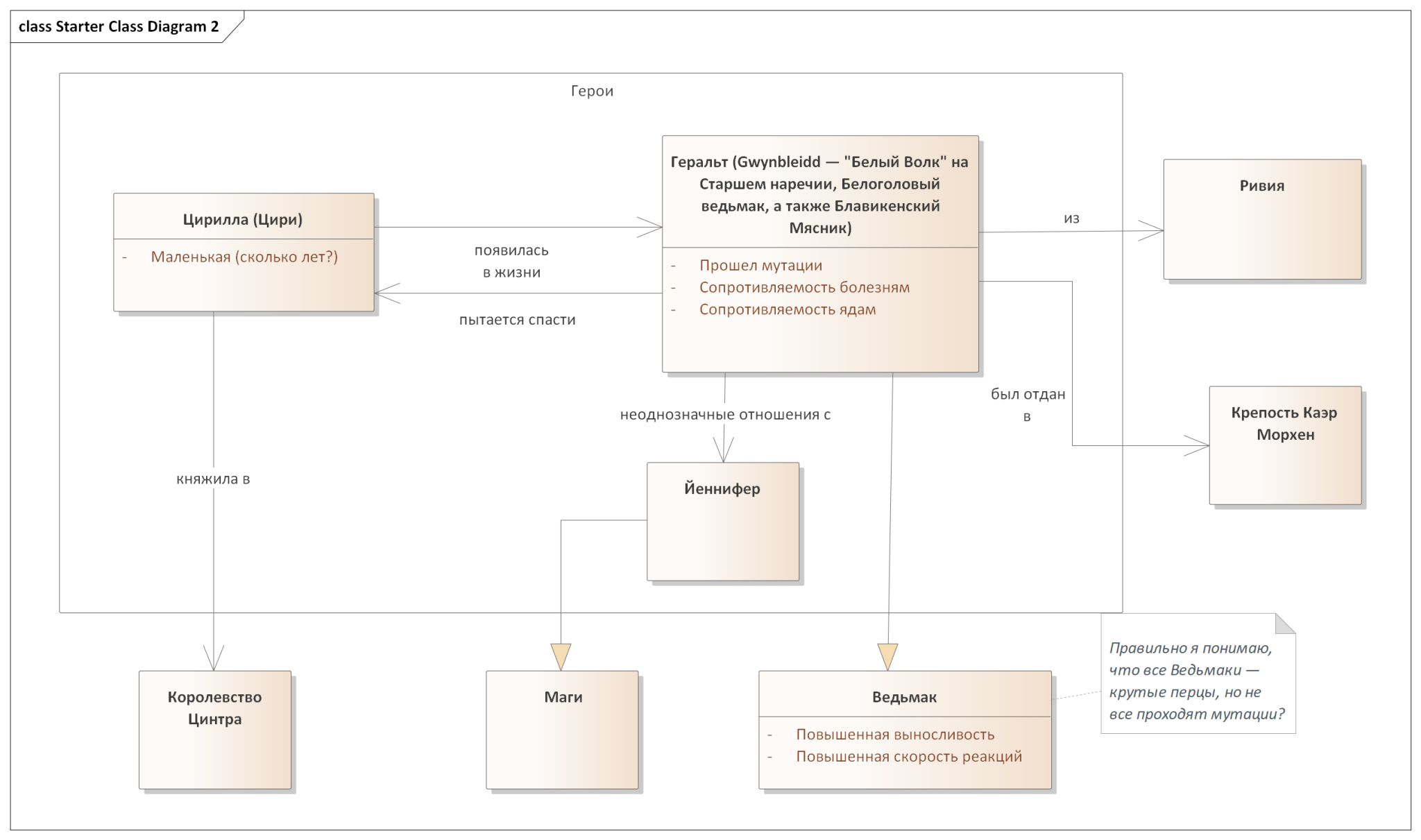
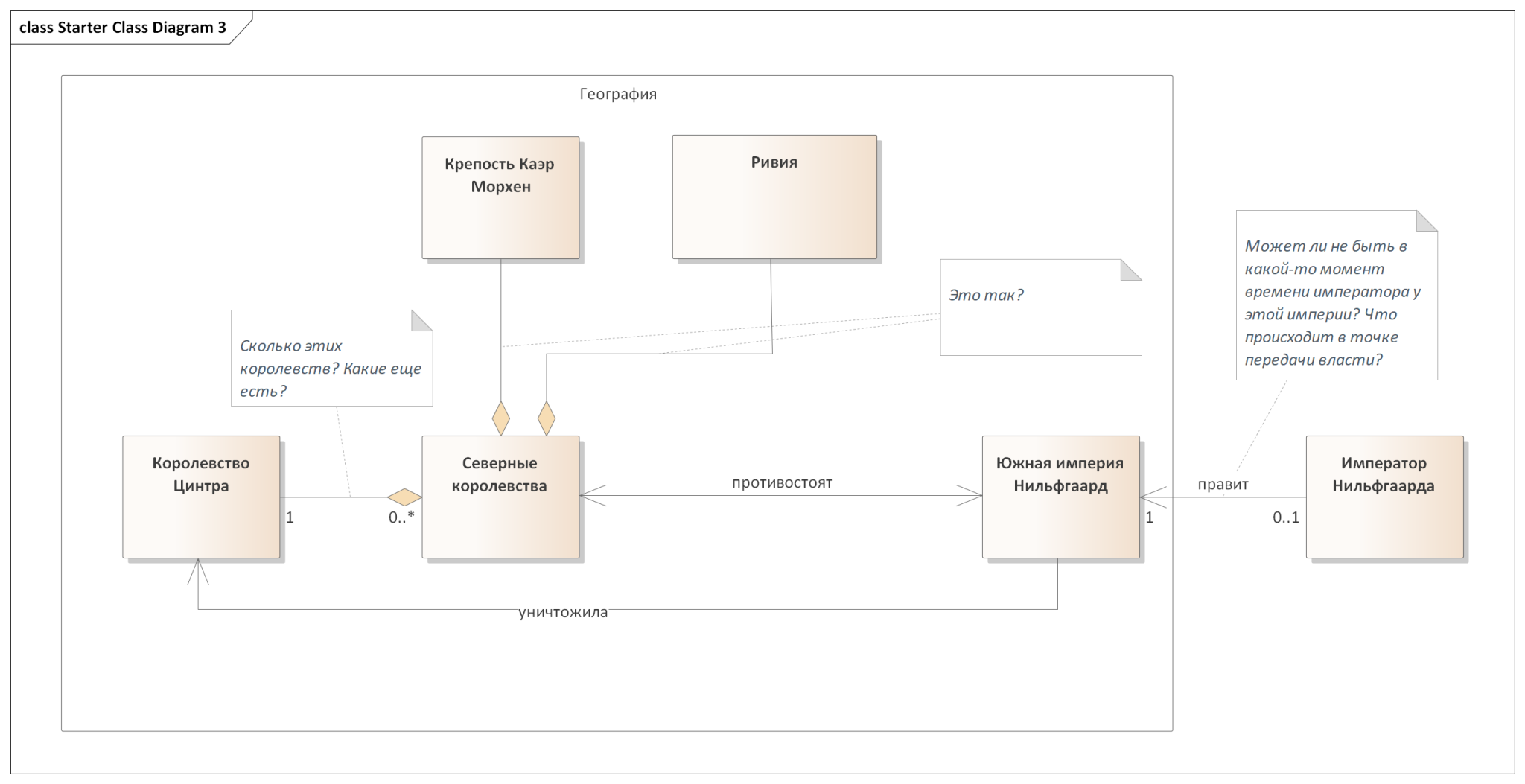
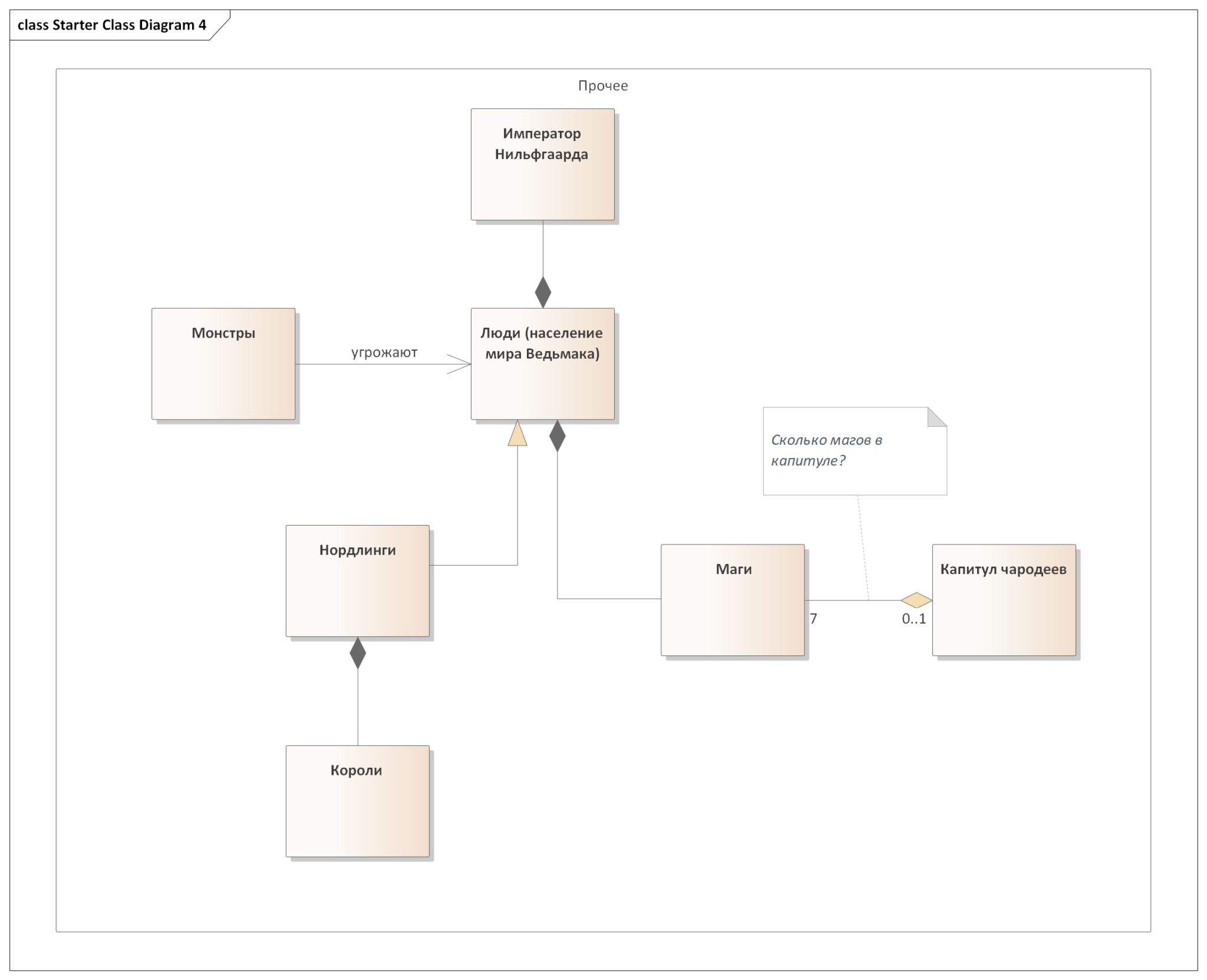
Как видите, модели а) стали читаемее (кто-то может поспорить, но тут я художник и так вижу), б) стали более насыщенными в плане информации, которую они несут (если уметь читать специфичные связи и множественности, конечно же) и в) натолкнули на ряд дополнительных вопросов.
Пара практических советов:
- Именуйте связи по направлению чтения стрелки, если мы говорим про ассоциацию (остальные связи в принципе в большинстве ситуаций именовать избыточно, ибо они самоочевидны).
- Используйте множественности для связей (не считая обобщения) везде, где это может нанести хоть какую-то возможную пользу. Это дополнительная информация, которая при проработке может дать кучу полезных инсайтов и служить источником ценных для решения бизнес-правил (например, «В компанию не может прийти пустой заказ»).
Теперь я могу, с одной стороны, взять такие модельки в охапку и принести на встречу с заказчиком, представив и объяснив ему их для подтверждения своего понимания предметной области или получения полезного фидбэка по ней. С другой стороны, я могу презентовать понимание области команде, расшифровывая непонятные аспекты по ходу презентации. И это вторая важная задача подобной модели, да и всех визуальных моделей в принципе, — упрощение коммуникации с заинтересованными лицами. Не в том смысле, что я могу отправить такой рисунок клиенту с посылом «Понимай, как хочешь — теперь наше общение будет быстрым и приятным», а в плане того, что демонстрируя это визуально, беседа по интересующим меня вопросам или попросту подтверждение своего понимания пройдет гораздо более эффективно, нежели я просто буду делать ему пересказ того, что я прочитал на каникулах.
Ну и в дальнейшем я могу либо выкинуть эти модельки после того, как они послужили исходным целям (но как-то это совсем не бережно), либо же продолжить поддерживать эти артефакты по мере изучения книжек, игр и сериала, дополняя и изменяя при необходимости (конечно же, по мере изучения этих источников модели дополнятся и увеличатся в десятки раз). Главное, как и со всеми подобными вспомогательными техниками — научиться тратить на проработку таких артефактов то количество времени, которое будет обосновано пользой, получаемой от их создания. Для этого подобное нужно попробовать и опытным путем нащупать личный баланс. Ну и изучение софта, дабы работать с ним быстро и дерзко, тоже никто не отменял.
—
Массу бессонных ночей и завершенных этапов бизнес-анализа спустя вы переходите к разработке требований к решению. Требования к решению, как многие знают, бывают функциональными и нефункциональными. Но вот что известно и чем оперирует в работе уже меньшее количество людей, так это то, что функциональные требования могут лежать в двух плоскостях (или, иными словами, на них бывает полезным взглянуть с двух ракурсов): поведение (функциональность) системы и данные, которыми сие поведение оперирует. Помним, да, что плоскость решений IT-аналитика — информационные системы? Информация тут прячется не случайно — это краеугольный камень программных решений. Они оперируют информацией, данными. Напрашивается нехитрый вывод о том, что с позиции требований полезно и самому посмотреть, и другим показать то, какими такими данными или какой информацией ваше решение должно оперировать. Оставим в стороне дискуссии о том, будете ли вы заниматься этим пластом требований — многое зависит от подхода к бизнес-анализу в сочетании с проектной методологией, вашего взгляда на то, что есть такое полнота требований, наличием или отсутствием совести, позиции планет на небе… — главное, чтобы это было осознанным решением, а не незнанием или неумением это делать. Но, допустим, вы все же погрузились в эту часть. Собственно, что вам в этом может помочь? Базой, которую вы в дальнейшем уже можете детализировать текстом (один из классических вариантов — словарь или глоссарий данных) или как-то по-иному, отлично послужит моделька, зовущаяся логической моделью данных. Сразу оговорюсь, что есть и более усложненные подходы, при которых аналитику рекомендуется проработать несколько уровней моделирования данных со своими пафосными названиями, но лично я ни разу не чувствовал нужды делать нечто подобное — всегда хватало одной модели, которую иначе можно назвать взглядом бизнес-аналитика на информацию, которой будет оперировать решение. Учитывая, что взор аналитика в принципе не должен быть затуманен способами реализации требований, подобная модель и зовется логической, то есть не привязанной к физической реализации. Аналитик (вот только не надо тут сейчас щеголять знаниями о том, что они порой делятся на бизнес- и системных) не знает и не особо должен желать знать заранее, будет ли для хранения информации использоваться база данных (и если да, то банальная реляционная или квантофазотронная) или данные будут храниться тупо в txt-файлах. А может они вообще не будут храниться в хранилище данных, а будут физически зашиты в код (но тут аккуратнее — тут уже вступают в силу нефункциональные требования изменяемости системы, поэтому на подобном уровне все же лучше разобраться и определиться с тем, как лучше поступать с информацией, которой система должна оперировать).
Хорошая новость в том, что логическая модель данных а) частенько вытекает из модели предметной области — многие из тех же сущностей и их атрибутов могут присутствовать и тут (что немудрено — решение автоматизирует предметную область), б) строится с использованием тех же диаграмм (например, UML Class Diagram залетит на ура, что мы дальше и рассмотрим), в) строится с применением тех же самых фишек, которые мы изучили ранее. А еще она, чаще всего, крутейше заходит команде разработки, и они будут слать вам лучи любви за подобный артефакт в составе требований. Плохая новость в том, что к ней надо подходить значительно более аккуратно и строго, нежели к предыдущей модели. Если модель предметной области — это взгляд вас как творца на понимание вами домена (и для одного и того же домена можно увидеть порой кардинально разные вариации моделей, которые будут вполне себе правильными aka будут вполне себе служить конечной цели), то логическая модель данных не будет (точнее, не должна) иметь кучи подобных вариаций — скорее всего, это будет указывать на ошибку в требованиях, которая потом так или иначе аукнется. В общем, давайте к примеру.
Давайте представим, что после череды итераций применения к заказчику паяльника и клещей вы определились, что сайт должен представлять собой каталог статей, которые описывают мир Ведьмака, с возможностью аутентифицированным юзерам оставлять комментарии к этим статьям. Статьи будут распределены по категориям, при этом обычный юзеры (как те, чью личность мы подтвердили, так и анонимусы) смогут статьи глядеть, а админ — создавать, править и творить прочий беспредел с ними. Пример у нас несложный, поэтому давайте слегка усложним: комменты должны проходить премодерацию после постинга со стороны админа с возможностью уведомлений автора о ее результате.
Это как раз тот самый пример, где содержимое модели данных слабо будет пересекаться с моделью предметной области. Мир Ведьмака со всем его внутренним устройством трансформируется в другие понятияв контексте программной системы. В какие? Давайте глянем на описание системы выше и подумаем, какой информацией решение будет оперировать. В системе будут статьи, у статей будут категории (можно было бы заявить, что категория — это всего лишь атомарный параметр статьи, как, допустим, ее название, но мы вкинем дополнительный контекст: клиент хотел бы иметь возможность для админов управления категориями (CRUD), включая порядок их расположения в меню сайта — и тут уже атомарный атрибут превращается в нечто составное, а следовательно — в отдельную сущность в модели). К статьям могут быть добавлены комментарии. В системе таки будут юзеры, ибо как-то нужно проводить регистрацию и последующие аутентификацию с авторизацией, что потребует хранения определенного набора информации по каждому юзеру. Ну и, если предположить, что фидбэк по проверке комментов будет доносится через некую внутреннюю систему уведомлений, то в системе также будут уведомления. Собственно, вот это все — информационное наполнение системы, которым будет оперировать уже вторая частичка функциональных требований — поведение системы.
Давайте перенесем все описанное текстом в модель и применим уже известные нам фишечки подобного моделирования. Получится как-то так:
Пара практических советов:
- Именуйте связи по направлению чтения стрелки, если мы говорим про ассоциацию (остальные связи в принципе в большинстве ситуаций именовать избыточно, ибо они самоочевидны).
- Используйте множественности для связей (не считая обобщения) везде, где это может нанести хоть какую-то возможную пользу. Это дополнительная информация, которая при проработке может дать кучу полезных инсайтов и служить источником ценных для решения бизнес-правил (например, «В компанию не может прийти пустой заказ»).
Теперь я могу, с одной стороны, взять такие модельки в охапку и принести на встречу с заказчиком, представив и объяснив ему их для подтверждения своего понимания предметной области или получения полезного фидбэка по ней. С другой стороны, я могу презентовать понимание области команде, расшифровывая непонятные аспекты по ходу презентации. И это вторая важная задача подобной модели, да и всех визуальных моделей в принципе, — упрощение коммуникации с заинтересованными лицами. Не в том смысле, что я могу отправить такой рисунок клиенту с посылом «Понимай, как хочешь — теперь наше общение будет быстрым и приятным», а в плане того, что демонстрируя это визуально, беседа по интересующим меня вопросам или попросту подтверждение своего понимания пройдет гораздо более эффективно, нежели я просто буду делать ему пересказ того, что я прочитал на каникулах.
Ну и в дальнейшем я могу либо выкинуть эти модельки после того, как они послужили исходным целям (но как-то это совсем не бережно), либо же продолжить поддерживать эти артефакты по мере изучения книжек, игр и сериала, дополняя и изменяя при необходимости (конечно же, по мере изучения этих источников модели дополнятся и увеличатся в десятки раз). Главное, как и со всеми подобными вспомогательными техниками — научиться тратить на проработку таких артефактов то количество времени, которое будет обосновано пользой, получаемой от их создания. Для этого подобное нужно попробовать и опытным путем нащупать личный баланс. Ну и изучение софта, дабы работать с ним быстро и дерзко, тоже никто не отменял.
—
Массу бессонных ночей и завершенных этапов бизнес-анализа спустя вы переходите к разработке требований к решению. Требования к решению, как многие знают, бывают функциональными и нефункциональными. Но вот что известно и чем оперирует в работе уже меньшее количество людей, так это то, что функциональные требования могут лежать в двух плоскостях (или, иными словами, на них бывает полезным взглянуть с двух ракурсов): поведение (функциональность) системы и данные, которыми сие поведение оперирует. Помним, да, что плоскость решений IT-аналитика — информационные системы? Информация тут прячется не случайно — это краеугольный камень программных решений. Они оперируют информацией, данными. Напрашивается нехитрый вывод о том, что с позиции требований полезно и самому посмотреть, и другим показать то, какими такими данными или какой информацией ваше решение должно оперировать. Оставим в стороне дискуссии о том, будете ли вы заниматься этим пластом требований — многое зависит от подхода к бизнес-анализу в сочетании с проектной методологией, вашего взгляда на то, что есть такое полнота требований, наличием или отсутствием совести, позиции планет на небе… — главное, чтобы это было осознанным решением, а не незнанием или неумением это делать. Но, допустим, вы все же погрузились в эту часть. Собственно, что вам в этом может помочь? Базой, которую вы в дальнейшем уже можете детализировать текстом (один из классических вариантов — словарь или глоссарий данных) или как-то по-иному, отлично послужит моделька, зовущаяся логической моделью данных. Сразу оговорюсь, что есть и более усложненные подходы, при которых аналитику рекомендуется проработать несколько уровней моделирования данных со своими пафосными названиями, но лично я ни разу не чувствовал нужды делать нечто подобное — всегда хватало одной модели, которую иначе можно назвать взглядом бизнес-аналитика на информацию, которой будет оперировать решение. Учитывая, что взор аналитика в принципе не должен быть затуманен способами реализации требований, подобная модель и зовется логической, то есть не привязанной к физической реализации. Аналитик (вот только не надо тут сейчас щеголять знаниями о том, что они порой делятся на бизнес- и системных) не знает и не особо должен желать знать заранее, будет ли для хранения информации использоваться база данных (и если да, то банальная реляционная или квантофазотронная) или данные будут храниться тупо в txt-файлах. А может они вообще не будут храниться в хранилище данных, а будут физически зашиты в код (но тут аккуратнее — тут уже вступают в силу нефункциональные требования изменяемости системы, поэтому на подобном уровне все же лучше разобраться и определиться с тем, как лучше поступать с информацией, которой система должна оперировать).
Хорошая новость в том, что логическая модель данных а) частенько вытекает из модели предметной области — многие из тех же сущностей и их атрибутов могут присутствовать и тут (что немудрено — решение автоматизирует предметную область), б) строится с использованием тех же диаграмм (например, UML Class Diagram залетит на ура, что мы дальше и рассмотрим), в) строится с применением тех же самых фишек, которые мы изучили ранее. А еще она, чаще всего, крутейше заходит команде разработки, и они будут слать вам лучи любви за подобный артефакт в составе требований. Плохая новость в том, что к ней надо подходить значительно более аккуратно и строго, нежели к предыдущей модели. Если модель предметной области — это взгляд вас как творца на понимание вами домена (и для одного и того же домена можно увидеть порой кардинально разные вариации моделей, которые будут вполне себе правильными aka будут вполне себе служить конечной цели), то логическая модель данных не будет (точнее, не должна) иметь кучи подобных вариаций — скорее всего, это будет указывать на ошибку в требованиях, которая потом так или иначе аукнется. В общем, давайте к примеру.
Давайте представим, что после череды итераций применения к заказчику паяльника и клещей вы определились, что сайт должен представлять собой каталог статей, которые описывают мир Ведьмака, с возможностью аутентифицированным юзерам оставлять комментарии к этим статьям. Статьи будут распределены по категориям, при этом обычный юзеры (как те, чью личность мы подтвердили, так и анонимусы) смогут статьи глядеть, а админ — создавать, править и творить прочий беспредел с ними. Пример у нас несложный, поэтому давайте слегка усложним: комменты должны проходить премодерацию после постинга со стороны админа с возможностью уведомлений автора о ее результате.
Это как раз тот самый пример, где содержимое модели данных слабо будет пересекаться с моделью предметной области. Мир Ведьмака со всем его внутренним устройством трансформируется в другие понятияв контексте программной системы. В какие? Давайте глянем на описание системы выше и подумаем, какой информацией решение будет оперировать. В системе будут статьи, у статей будут категории (можно было бы заявить, что категория — это всего лишь атомарный параметр статьи, как, допустим, ее название, но мы вкинем дополнительный контекст: клиент хотел бы иметь возможность для админов управления категориями (CRUD), включая порядок их расположения в меню сайта — и тут уже атомарный атрибут превращается в нечто составное, а следовательно — в отдельную сущность в модели). К статьям могут быть добавлены комментарии. В системе таки будут юзеры, ибо как-то нужно проводить регистрацию и последующие аутентификацию с авторизацией, что потребует хранения определенного набора информации по каждому юзеру. Ну и, если предположить, что фидбэк по проверке комментов будет доносится через некую внутреннюю систему уведомлений, то в системе также будут уведомления. Собственно, вот это все — информационное наполнение системы, которым будет оперировать уже вторая частичка функциональных требований — поведение системы.
Давайте перенесем все описанное текстом в модель и применим уже известные нам фишечки подобного моделирования. Получится как-то так:
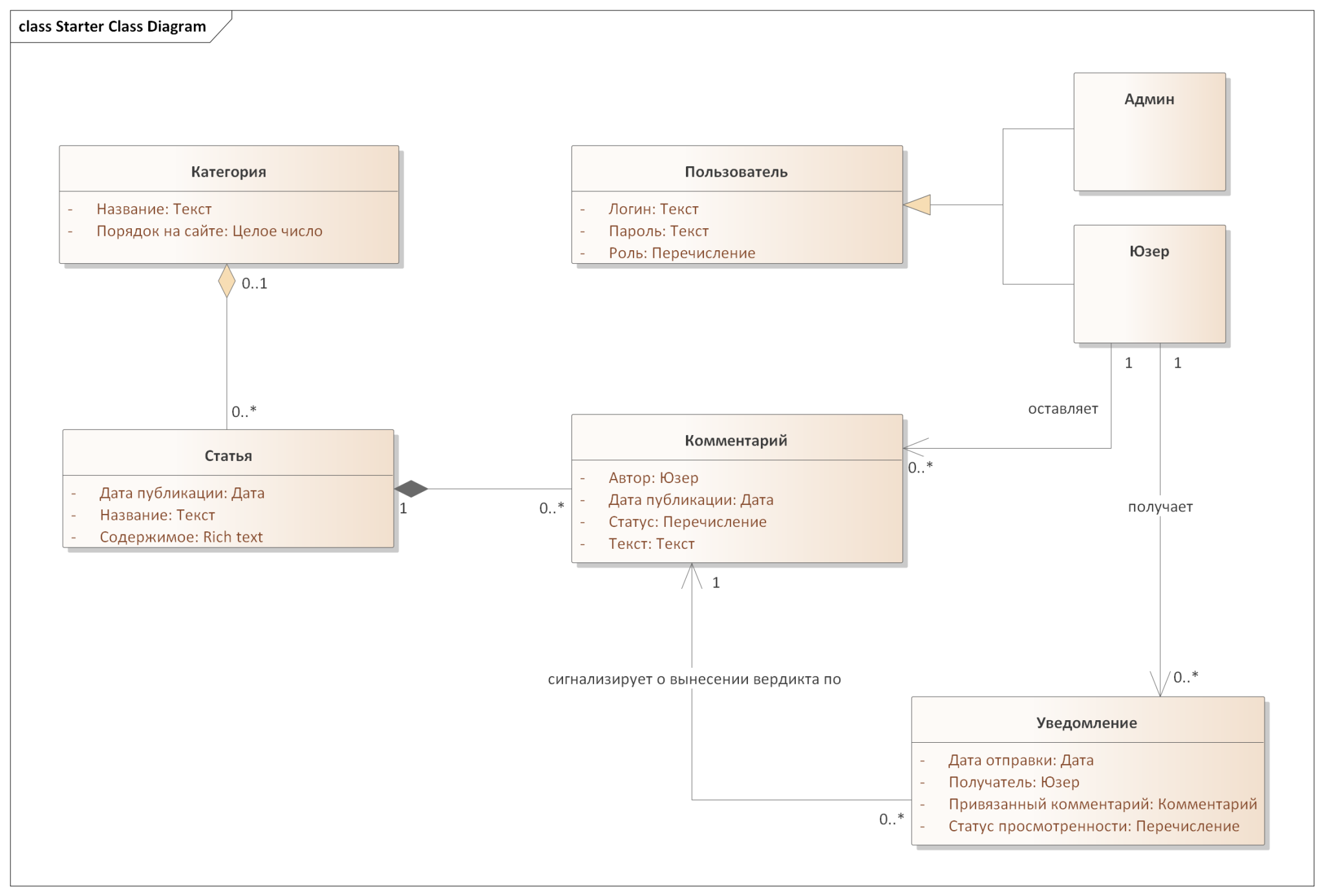
Давайте изучим ряд деталей:
1) Для атрибутов, в отличие от модели предметной области, указаны типы данных. Да что уж там: в модели предметной области и атрибутов-то особо и не было в классах, не считая точечных мест, где это нужно было, чтобы правильно отразить понимание исходного текста. Типы данных, как и все остальное, логические — описаны человеческим языком и в человеческом же (аналитика то бишь) представлении (причем не фиксированным — вы можете выбирать удобные для вас и команды термины). В физической модели данных они трансформируются в нечто, присущее выбранному подходу к реализации, и вместо всяких чисел и текста могут появиться угрожающие char, string, int и прочие. Но, как мы уже выше говорили, проблемы реализации шерифа не колышут. В целом, проработка атрибутов и их типов данных — полезная и важная часть требований к данным, но только имейте в виду, что если вы будете сопровождать такую модель словарем данных, то подобное (детализация атрибутов и их специфик в модели) может стать избыточным дублированием информации.
Два интересных типа данных, которые вы можете использовать по такой же концепции по согласованию с командой (а именно она — основной потребителей этих требований), либо же заменить чем-то более удобным для них:
- Перечисление. Это набор из точно известного заранее списка значений. В отличие, например, от Текста, где значение атрибута для конкретного экземпляра класса может быть произвольным. Например, Статус Комментария будет всегда «Одобрен», «Отклонен» либо «Не проверен» — всегда одним из трех фиксированных значений. Что именно это за значения, вы укажете в словаре данных или прочих поясняющих модель материалах.
- Типы данных, которые совпадают с названием какой-либо сущности данных. Например, у Комментария Автор имеет тип данных Юзер. Что это за фигня такая? А давайте подумаем. Когда мы говорим, что у комментария есть автор, мы как себе представляем эту информацию? Текст? А какой тогда текст — логин автора? Если что, у автора нет имени — это прослеживается по атрибутам сущности Юзер. Можно сделать и так — это альтернативный вариант подачи подобной информации: вы можете добавить увязывающие сущности атрибуты и оставить их в простом атомарном виде (например, показать, что именно атрибут Логин будет связкой между Юзерами и их Комментариями). Мне же по душе несколько иной подход: показать, что автор у Комментария — это экземпляр сущности данных Юзер со всем своим внутренним наполнением, а потому у него сложный композитный тип данных — собственно, сама наша сущность Юзер.
Кстати, минусики на диаграмме перед наименованиями атрибутов также имеют значение — можете поискать описание семантики диаграмм классов в UML. Но не для аналитика, а потому тут это просто оставлено так, как инструмент нарисовал по умолчанию.
2) Поясню некоторые связи и логику за ними:
- Комментарий — Статья. Это композиция, т. к. Комментарий не актуален без родительской статьи. При удалении/архивации/whatever статьи Комментарии будут так же безжалостно устранены. Комментарий без Статьи не имеет смысла, причем он может быть оставлен ровно под одной Статьей. А вот у Статьи, в свою очередь, может как не быть Комментариев, так и быть тьма тьмущая (и мы могли бы узнать верхний лимит, но а надо ли?).
- Статья — Категория. Тут немного сложнее и добавлен авторский взгляд на требования (что в реальном проекте, конечно же, должно быть уточнено и согласовано, с кем нужно). Это агрегация, т. к. подразумевается, что при удалении Категории система либо предложит оставить Статью в некотором «некатегоризированном» множестве, либо предложит перенести в другую категорию. Но представим, что статьи точно при этом не должны удаляться — это не есть желаемое поведение. Соответственно, Статья может как быть в рамках некоей Категории, так и существовать вне ее — в неком астральном мире некатегоризированных статей, которые не отобразятся для обычных пользователей, пока им не назначить Категорию.
3) Админ и Юзер выделены в отдельные сущности, дабы показать отношение лишь определенного подвида Пользователей к Комментариям и Уведомлениям. Если бы не это, то подобное выделение было бы избыточным, т. к. это всего лишь Пользователи с разным значением атрибута Роль.
Что я могу с такой моделькой сделать? Общие цели — ровно такие же, как и для модели предметной области: фасилитация собственного анализа и повышение эффективности коммуникаций. Ну а если конкретнее, то, во-первых, проделывая подобную работу, вам на ум придет масса полезных вопросов: может ли статья не иметь категории и, если да, как подобное необходимо системе обработать в разных ситуациях? Какого типа контент может присутствовать в статье? Что делать с комментариями при удалении статьи? Какие состояния могут быть у комментариев? Какую информацию необходимо пользователям заполнить о «подставь тут название сущности»? И т. д. Как и с любым взглядом, когда вы посмотрите на требования под определенным углом, вы получите ряд инсайтов, которые сходу не заметили бы. Тут мы смотрим на требования к решению в разрезе данных. Когда задумаемся о поведении системы в различных ситуациях, или о требованиях к безопасности, или об ограничениях реализации и пр., мы получим новые знания и появятся новые вопросы.
Во-вторых, это артефакт, содержащий требования. Его можно и нужно отдавать тем, кто требования будет реализовывать, а после и проверять их реализацию. Запихните в спеку, разместите в Confluence, сошлитесь сюда из ваших сторей — это всяко дополнительные требования, которые повысят вероятность нанесения счастья бизнес-анализом. Тут же есть и вторая полезняшка: при грамотной трассировке вы и сами сократите вероятность некачественности своих же требований (полнота, необходимость, противоречивость и т. п.). Например, имея данные в центре решения и взяв их за базу для поведенческих требований, вы с гораздо меньшей вероятностью сделаете что-то лишнее или не сделаете что-то нужное. Простой пример. Вы решили, что для Статьи важны Дата публикации и Название. На каком-то этапе вы крутите в голове CRUDL для такой сущности данных, как Статья. Допустим, у вас есть редактирование статьи админом. Имея подобную модель, теперь вы едва ли забудете, что при редактировании важно дать (или не дать — сами уже решайте — главное, что вы это осмыслите) возможность поменять и название статьи, а не только контент. Или же задуматься, а зачем вы выделили Дату публикации? Если это не фигурирует в поведении от слова «совсем», то и зачем это в данных? Это понадобится в будущем или все же полезным будет показать дату пользователям на UI? Или, может, выкинуть этот параметр из требований?
Ну и никто не отменял полезность модели в контексте согласования с внешними стейкхолдерами. Да, она не так проста в понимании (а в понимании для неподготовленного человека и вовсе едва ли осиливаема), плюс некоторым еще надо взгляд помочь подобным образом сфокусировать. Но тем не менее (хоть и не скажу, что это важная составляющая хода любого проекта), с некоторыми представителями заказчика бывает полезным за кружечкой пива обсудить требования и в таком разрезе — как и в личном анализе, дополнительные плоскости могут помочь выявить дополнительные нюансы. Как-то раз за неимением подобной модели и нераскрытием подобных нюансов (множественностей между классами данных, в частности) в моей практике был завален проект, что как бы намекает.
Вот такие есть две интересные мини-техники. За кадром, конечно, осталось много полезных нюансов по применению каждой из моделей в той или иной ситуации, но мы ведь знаем, да, что лучше просто взять и попробовать в бою?
1) Для атрибутов, в отличие от модели предметной области, указаны типы данных. Да что уж там: в модели предметной области и атрибутов-то особо и не было в классах, не считая точечных мест, где это нужно было, чтобы правильно отразить понимание исходного текста. Типы данных, как и все остальное, логические — описаны человеческим языком и в человеческом же (аналитика то бишь) представлении (причем не фиксированным — вы можете выбирать удобные для вас и команды термины). В физической модели данных они трансформируются в нечто, присущее выбранному подходу к реализации, и вместо всяких чисел и текста могут появиться угрожающие char, string, int и прочие. Но, как мы уже выше говорили, проблемы реализации шерифа не колышут. В целом, проработка атрибутов и их типов данных — полезная и важная часть требований к данным, но только имейте в виду, что если вы будете сопровождать такую модель словарем данных, то подобное (детализация атрибутов и их специфик в модели) может стать избыточным дублированием информации.
Два интересных типа данных, которые вы можете использовать по такой же концепции по согласованию с командой (а именно она — основной потребителей этих требований), либо же заменить чем-то более удобным для них:
- Перечисление. Это набор из точно известного заранее списка значений. В отличие, например, от Текста, где значение атрибута для конкретного экземпляра класса может быть произвольным. Например, Статус Комментария будет всегда «Одобрен», «Отклонен» либо «Не проверен» — всегда одним из трех фиксированных значений. Что именно это за значения, вы укажете в словаре данных или прочих поясняющих модель материалах.
- Типы данных, которые совпадают с названием какой-либо сущности данных. Например, у Комментария Автор имеет тип данных Юзер. Что это за фигня такая? А давайте подумаем. Когда мы говорим, что у комментария есть автор, мы как себе представляем эту информацию? Текст? А какой тогда текст — логин автора? Если что, у автора нет имени — это прослеживается по атрибутам сущности Юзер. Можно сделать и так — это альтернативный вариант подачи подобной информации: вы можете добавить увязывающие сущности атрибуты и оставить их в простом атомарном виде (например, показать, что именно атрибут Логин будет связкой между Юзерами и их Комментариями). Мне же по душе несколько иной подход: показать, что автор у Комментария — это экземпляр сущности данных Юзер со всем своим внутренним наполнением, а потому у него сложный композитный тип данных — собственно, сама наша сущность Юзер.
Кстати, минусики на диаграмме перед наименованиями атрибутов также имеют значение — можете поискать описание семантики диаграмм классов в UML. Но не для аналитика, а потому тут это просто оставлено так, как инструмент нарисовал по умолчанию.
2) Поясню некоторые связи и логику за ними:
- Комментарий — Статья. Это композиция, т. к. Комментарий не актуален без родительской статьи. При удалении/архивации/whatever статьи Комментарии будут так же безжалостно устранены. Комментарий без Статьи не имеет смысла, причем он может быть оставлен ровно под одной Статьей. А вот у Статьи, в свою очередь, может как не быть Комментариев, так и быть тьма тьмущая (и мы могли бы узнать верхний лимит, но а надо ли?).
- Статья — Категория. Тут немного сложнее и добавлен авторский взгляд на требования (что в реальном проекте, конечно же, должно быть уточнено и согласовано, с кем нужно). Это агрегация, т. к. подразумевается, что при удалении Категории система либо предложит оставить Статью в некотором «некатегоризированном» множестве, либо предложит перенести в другую категорию. Но представим, что статьи точно при этом не должны удаляться — это не есть желаемое поведение. Соответственно, Статья может как быть в рамках некоей Категории, так и существовать вне ее — в неком астральном мире некатегоризированных статей, которые не отобразятся для обычных пользователей, пока им не назначить Категорию.
3) Админ и Юзер выделены в отдельные сущности, дабы показать отношение лишь определенного подвида Пользователей к Комментариям и Уведомлениям. Если бы не это, то подобное выделение было бы избыточным, т. к. это всего лишь Пользователи с разным значением атрибута Роль.
Что я могу с такой моделькой сделать? Общие цели — ровно такие же, как и для модели предметной области: фасилитация собственного анализа и повышение эффективности коммуникаций. Ну а если конкретнее, то, во-первых, проделывая подобную работу, вам на ум придет масса полезных вопросов: может ли статья не иметь категории и, если да, как подобное необходимо системе обработать в разных ситуациях? Какого типа контент может присутствовать в статье? Что делать с комментариями при удалении статьи? Какие состояния могут быть у комментариев? Какую информацию необходимо пользователям заполнить о «подставь тут название сущности»? И т. д. Как и с любым взглядом, когда вы посмотрите на требования под определенным углом, вы получите ряд инсайтов, которые сходу не заметили бы. Тут мы смотрим на требования к решению в разрезе данных. Когда задумаемся о поведении системы в различных ситуациях, или о требованиях к безопасности, или об ограничениях реализации и пр., мы получим новые знания и появятся новые вопросы.
Во-вторых, это артефакт, содержащий требования. Его можно и нужно отдавать тем, кто требования будет реализовывать, а после и проверять их реализацию. Запихните в спеку, разместите в Confluence, сошлитесь сюда из ваших сторей — это всяко дополнительные требования, которые повысят вероятность нанесения счастья бизнес-анализом. Тут же есть и вторая полезняшка: при грамотной трассировке вы и сами сократите вероятность некачественности своих же требований (полнота, необходимость, противоречивость и т. п.). Например, имея данные в центре решения и взяв их за базу для поведенческих требований, вы с гораздо меньшей вероятностью сделаете что-то лишнее или не сделаете что-то нужное. Простой пример. Вы решили, что для Статьи важны Дата публикации и Название. На каком-то этапе вы крутите в голове CRUDL для такой сущности данных, как Статья. Допустим, у вас есть редактирование статьи админом. Имея подобную модель, теперь вы едва ли забудете, что при редактировании важно дать (или не дать — сами уже решайте — главное, что вы это осмыслите) возможность поменять и название статьи, а не только контент. Или же задуматься, а зачем вы выделили Дату публикации? Если это не фигурирует в поведении от слова «совсем», то и зачем это в данных? Это понадобится в будущем или все же полезным будет показать дату пользователям на UI? Или, может, выкинуть этот параметр из требований?
Ну и никто не отменял полезность модели в контексте согласования с внешними стейкхолдерами. Да, она не так проста в понимании (а в понимании для неподготовленного человека и вовсе едва ли осиливаема), плюс некоторым еще надо взгляд помочь подобным образом сфокусировать. Но тем не менее (хоть и не скажу, что это важная составляющая хода любого проекта), с некоторыми представителями заказчика бывает полезным за кружечкой пива обсудить требования и в таком разрезе — как и в личном анализе, дополнительные плоскости могут помочь выявить дополнительные нюансы. Как-то раз за неимением подобной модели и нераскрытием подобных нюансов (множественностей между классами данных, в частности) в моей практике был завален проект, что как бы намекает.
Вот такие есть две интересные мини-техники. За кадром, конечно, осталось много полезных нюансов по применению каждой из моделей в той или иной ситуации, но мы ведь знаем, да, что лучше просто взять и попробовать в бою?
