
Поговорим о такой классной и важной штуке в работе с требованиями, как требования к данным (data requirements). В этой заметке я постараюсь убедительно показать, почему таким требованиям важно уделять время и силы, к чему может привести их игнорирование (и наоборот — какие плюшки можно получить от работы с ними) и что включает в себя работа с такими требованиями.
Минутка контекста. Мы как IT-аналитики работаем с информационными системами. Информационные системы работают с информацией: их суть в том, чтобы самостоятельно либо в виде функций для пользователей позволить этой самой информацией оперировать (создавать, редактировать, удалять, просматривать — магическая аббревиатура CRUD, которую аналитики слышали не раз). Что такое требования к данным? Это как раз требования к тому, какой информацией система должна оперировать.
В целом, я адепт подхода, который можно описать так: чем с большего количества сторон мы взглянем на требования, тем качественнее итоговые требования к системе будут в плане полноты, непротиворечивости и т. п. Конечно, бывают ситуации, когда важнее сделать работу быстрее, нежели многограннее, но требования к данным относятся к тому аспекту, жертвовать которым в угоду экономии времени я не рекомендую, и дальше поясню, почему.
Требования к данным — это когда мы глядим на целевую систему не в разрезе ее поведения или качественных аспектов, а со стороны того, с какой информацией работает поведение системы.
Где искать требования к данным в рамках известных классификаций требований? Большинство аналитиков знают классификации Вигерса и BABOK, и вероятно даже встречали такое понятие, как требования к данным, но как-то сложно припомнить их явное место в тех классификациях, не так ли? Агась, ибо их там нет. И это такое себе, конечно, явление. Минутка нудных раскопок в известных теориях (это, кстати, может пригодиться для рассуждений на собеседованиях): что говорят известные источники про этот вид требований?
а) Отец (Karl Wiegers, Joy Beatty — Software Requirements, 3rd edition) пишет следующее касательное своей иерархии требований: Data requirements are not shown explicitly in this diagram. Functions manipulate data, so data requirements can appear throughout the three levels.
Я не понимаю, как требования к данным могут фигурировать на трех его уровнях требований, и по мне это один из тех моментов, где дядюшка либо преисполнился в недостижимых для обывателя материях, либо отвлекся на котиков в моменте. Что такое, например, требования к данным на уровне бизнес-требований, которые бизнес-цели заказчика? На мой взгляд, требования к данным не могут лежать нигде, кроме уровня требований к решению (solution requirements), т. к. это именно то, чем будет оперировать решение, работающее с информацией.
Я не понимаю, как требования к данным могут фигурировать на трех его уровнях требований, и по мне это один из тех моментов, где дядюшка либо преисполнился в недостижимых для обывателя материях, либо отвлекся на котиков в моменте. Что такое, например, требования к данным на уровне бизнес-требований, которые бизнес-цели заказчика? На мой взгляд, требования к данным не могут лежать нигде, кроме уровня требований к решению (solution requirements), т. к. это именно то, чем будет оперировать решение, работающее с информацией.
б) BABOK (3): functional requirements: describe the capabilities that a solution must have in terms of the behaviour and information that the solution will manage. Собственно, все — BABOK выше каких-то там жалких деталей. Т. е. BABOK мельком упоминает требования к данным в рамках функциональных требований.
в) IREB: Functional requirements concern a result or behavior that shall be provided by a function of a system. This includes requirements for data or the interaction of a system with its environment. Т. е. снова-таки это часть функциональных требований.
Я согласен с последними двумя источниками и не согласен либо не понимаю грандиозный замысел отца Карла, ибо функции программных систем оперируют информацией, а потому два ключевых вида функциональных требований (как подвида требований к решению) рекомендую иметь такие:
- Требования к поведению (системы)
- Требования к данным (системы)
Что такое проработка требований к данным в рамках работы с требованиями? Фактически это означает выделить отдельное место в вашей документации под это и, как и с прочими требованиями, извлекать, думать, фиксировать и управлять этим набором требований. Причем я рекомендую делать это в параллели с проработкой поведенческих функциональных требований, а иногда даже и до, т. к. поведение системы часто будет состоять в том, чтобы “CRUDить” то, что вы опишете в требованиях к данным.
Далее я предложу несложный алгоритм того, как с ними работать, какие техники использовать для этого, плюс параллельно мы рассмотрим пример. С него и начнем:
Вы путем общения с заказчиком и иными стейкхолдерами (далее будут называть их ЗЛ, заинтересованными лицами) пришли к тому, что надо сделать несложный Интернет-магазин, в котором ключевое — это страничка с общей информацией о магазине, просмотром каталога товаров и возможностью что-то себе заказать.
Мы пропустим работу с бизнес-требованиями и требованиями ЗЛ (включая пользователей), т. к. мы определили уже, что требования к данным — на уровне требований к решению (третьем уровне). Т. е. представим, что в условиях мифического водопадного бизнес-анализа мы перешли к проектированию наполнения решения в контексте требований.
Что первым придет на ум нехитрому в плане тулсета аналитику? Ну что, народ, погнали сторьки писать, юз кейсы или как-то еще разбивать систему на кусочки и описывать поведение этих кусочков.
1) Что рекомендую я в качестве первого шага в контексте нашей темы (и его точно лучше сделать до написания историй): то, что рекомендовал еще отец Вигерс — начать с контекстной диаграммы. Контекстная диаграмма — это не часть требований к данным (это относится к проработке скоупа решения), но отличная стартовая точка для перехода к ним.
Мистер Вигерс выдал замечательную мысль: A good place to start with data requirements is with the input and output flows on the system’s context diagram. These flows represent major data elements at a high level of abstraction, which the BA can refine into details as elicitation progresses.
Я не буду в деталях останавливаться на том, как строить эту диаграмму — отец отлично это описал в своей книге. Приведу лишь ключевое, дабы освежить память. Контекстная диаграмма показывает границы решения (но не его наполнение — в этом плане у нас остается черный ящик) и внешних субъектов (люди, аппаратные и программные системы), которые с решением напрямую взаимодействуют. А еще она показывает суть этих взаимодействий в терминах информации, которой эти субъекты обмениваются с решением. Строится с помощью нотации DFD (Data Flow Diagram).
Давайте построим такую диаграмму, пользуясь исходным условием для примера:
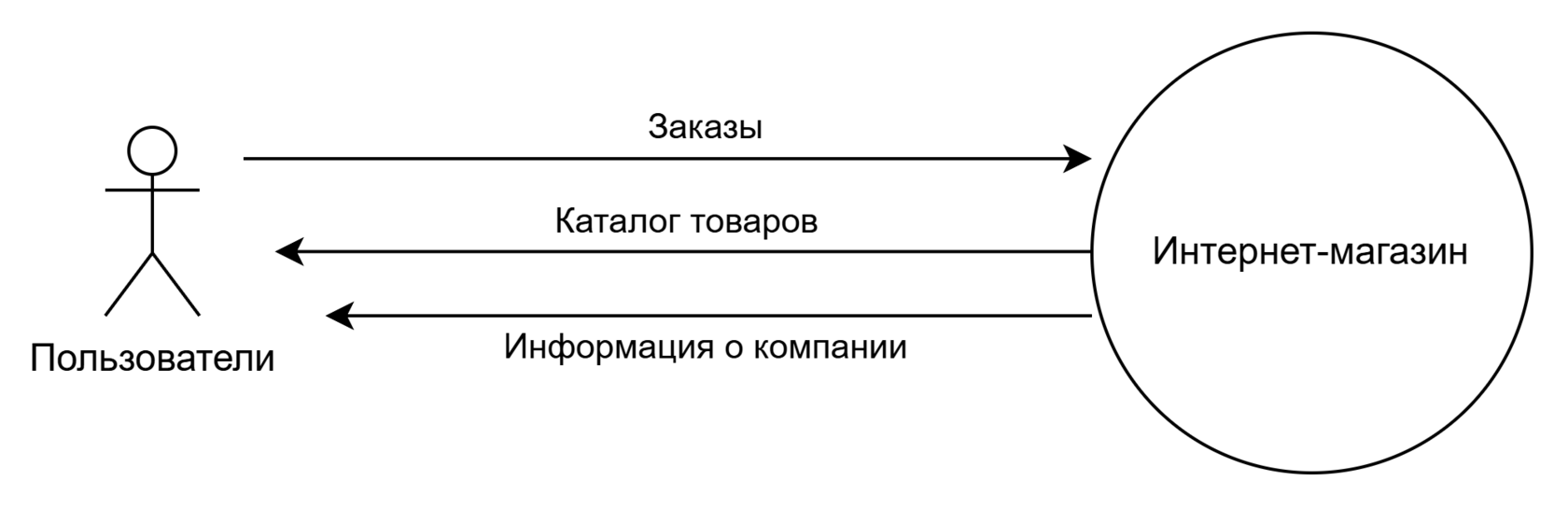
Еще раз подчеркну, что на стрелочках (которые показывают взаимодействие внешних субъектов с решением) — не действия, а информация. Именно поэтому эта диаграмма и является отличной точкой для старта проработки этих самых данных.
2) На каком-то из этапов вашей магии бизнес-анализа (например, уже сейчас) рекомендую применить технику CRUDL, т. к. она непосредственно связана с требованиями к данным. Опять-таки, вкратце, ибо есть, где детально вчитаться (трямс): CRUDL позволяет проанализировать скоуп решения на предмет его полноты и применяется по отношению к тем требованиям к данным, которые уже видны на этапе применения этой техники.
CRUDL — это чеклист типовых операций над данными:
- Create — создание объекта
- Read — просмотр информации об объекте
- Update — редактирование/изменение информации об объекте
- Delete — удаление объекта
- List — просмотр списка объектов (второстепенная, если сравнивать с предыдущими, операция: практически всегда, когда объектов много, для того, чтобы просмотреть или изменить информацию об конкретном объекте, вначале нужно просмотреть их список).
Введем в этой точке два важных понятия из области требований к данным: сущности данных (data entities, data objects, data classes) и их атрибуты (attributes). Сущности — это крупные куски данных, состоящие из более мелких кусочков информации. Атрибуты — эти самые атомарные кусочки. Т. е. если кусок информации можно разбить на что-то более детальное, то это сущность. Вы можете найти и иные, более сложные определения, но я бы оставил именно такое нехитрое понимание, т. к. его хватит для наших задач.
Информация на контекстной диаграмме — это сущности данных, т. к. Заказ — это явно какой-то набор информации, как и Информация о компании и Товар. И тут заметьте — я сразу перешел к понятию “Товар”, т. к. каталог товаров — это не что-то, имеющее самостоятельное информационное наполнение, а всего лишь много Товаров (т. е. несколько объектов класса Товар), которые будут отображаться на страничке. Точно так же в системе может быть много Заказов. Возможна вариация, когда Каталог или Категория Товаров будут отдельными сущностями данных (если, к примеру, в системе Товары должны показываться в рамках настраиваемых Каталогов), но это уже будет усложнением исходного условия.
Применим CRUDL к этим сущностям данных и построим табличку, в которой укажем, что у нас видится в плане полноты типовых операций над ними (плюс в табличке я сразу очерчу базовые вопросы к заказчику или иным ЗЛ и ответы, которые мы от них получили):
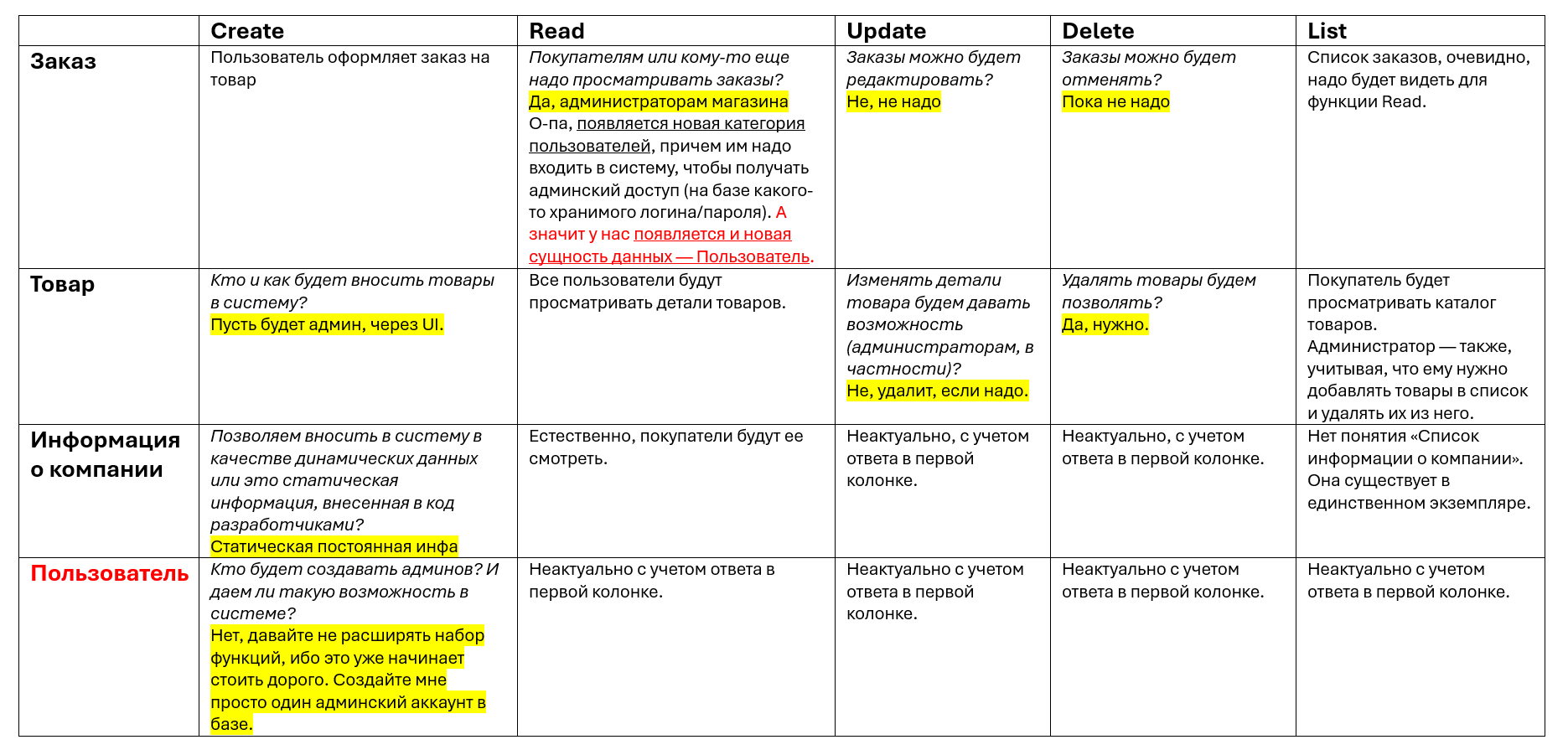
Теперь мы уже больше знаем о скоупе решения, а потому давайте добавим это в исходное описание и дополним контекстную диаграмму:
Сделать несложный Интернет-магазин, в котором ключевое — это страничка с общей информацией о магазине, просмотром каталога товаров и возможностью что-то себе заказать. Администраторы магазина (в виде единственного предсозданного аккаунта) смогут просматривать сделанные заказы. Они же смогут добавлять/удалять товары в каталог, просматривая их при этом.
И вот у нас первое неоспоримое преимущество работы с требованиями к данным: изучив типовые операции над ними с помощью CRUDL, мы сделали скоуп решения в плане функций значительно полнее — закрыли очевидные пробелы. А это уже лютый вин для аналитика, т. к. если бы мы оставили скоуп в виде исходных текстовок и пошли его послушно делать, мы упустили бы почти половину неявных (не проговоренных в явном виде) требований.
3) Первый ключевой компонент требований к данным в нашей документации, который стоит начать прорабатывать уже сейчас (а дорабатывать в параллели с описанием историй, юз кейсов и иже с ними) — логическая модель данных (Logical Data Model, LDM). Сразу оговорюсь, что в теориях бывают и более сложные подходы, в которых аналитику рекомендуется проработать несколько уровней моделирования данных с разными красивыми названиями, но мне всегда хватало одной модели, которую иначе можно назвать взглядом бизнес-аналитика на информацию, которой будет оперировать решение.
Учитывая, что аналитику не стоит привязываться к способам реализации требований, модель зовется логической (то есть не привязанной к физической реализации). Аналитик (если он не системный и не подрабатывает на парт-тайм архитектором) не знает заранее, будет ли для физического хранения информации использоваться база данных (и какого вида) или данные будут храниться тупо в txt-файлах.
Логическая модель данных показывает то, какой информацией будет оперировать система, и как эта информация между собой связана. Такую модель можно рисовать с помощью разных нотаций (IDEF, ER, Crow's Foot, UML). Мне по душе UML и в частности UML Class Diagram.
Как мы строим такую модель? Вот тут и тут я описывал это детально, и ниже я вкратце затрону ключевые моменты, но за более подробными раскопками и другими примерами рекомендую сходить по ссылкам, если почувствуете, что информации не хватает.
а) Вначале давайте внесем наши сущности данных в виде прямоугольников (классов в терминах UML Class Diagram):
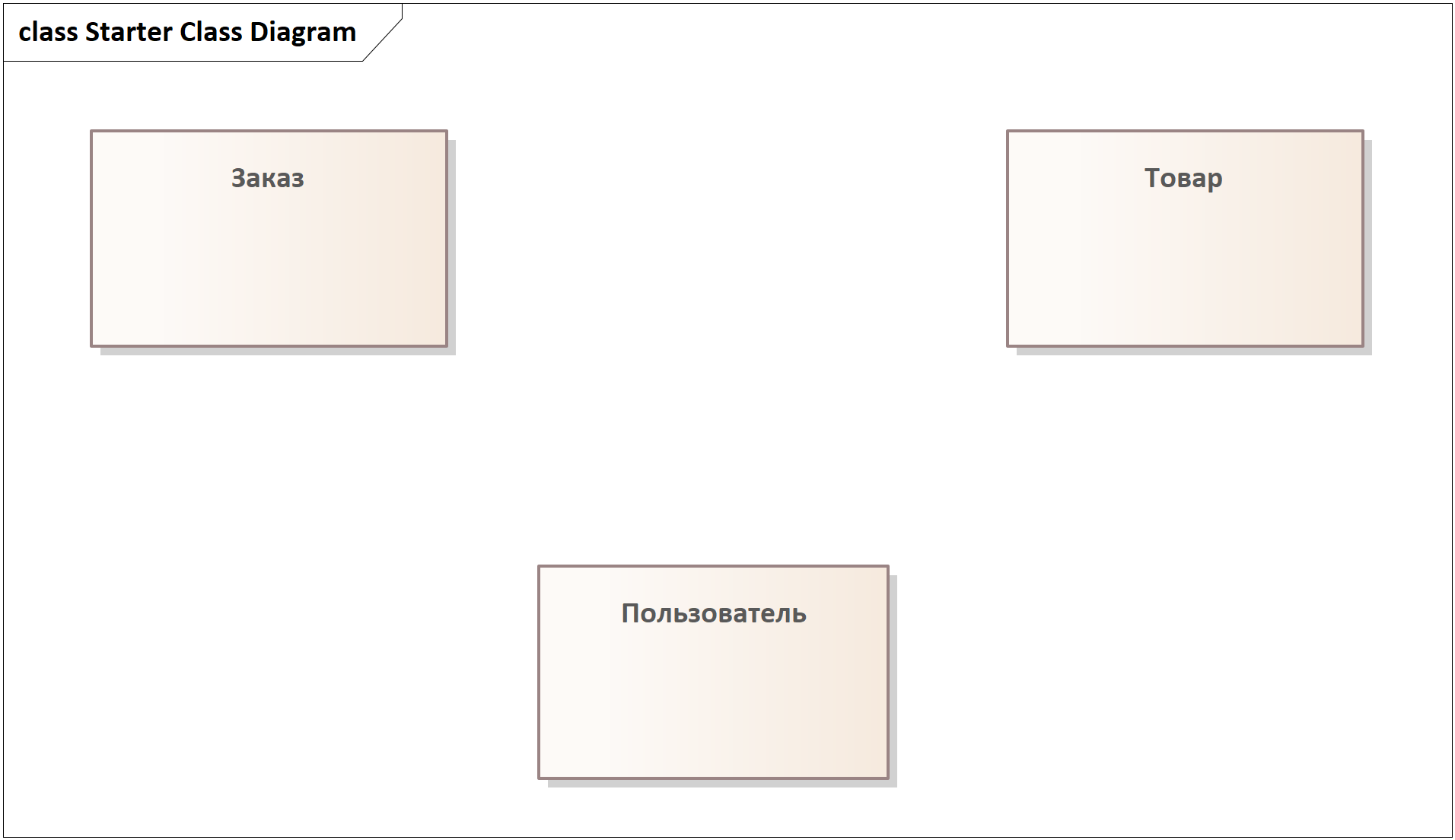
Пара пояснений:
- Почему я не внес Информацию о компании? Для новичков это может быть не очень понятным, и если вы внесете такую сущность данных, это не будет серьезной ошибкой, но с позиции опыта я знаю, что это не часть данных. Когда мы говорим про данные системы, нас интересуют динамические данные, т. е. та информация, которая имеет вероятность меняться, причем не переписыванием кода системы (т. е. информация, которую либо юзер может внести, либо система может откуда-то получить). Статическая информация — это то, что в систему “захардкодят” разработчики. Судя по ответам стейкхолдеров, Информация о компании — оно и есть, то бишь разработчики просто внесут фиксированную информацию о компании в код веб-странички, плюс у этого класса данных не может быть экземпляров (т. е. у нас не может быть нескольких Информаций о компании) и к такой информации неприменимо понятие CRUDL, не считая просмотра этой самой странички.
- Почему я тогда внес Пользователя (который представляет именно администратора, т. к. для покупателей нам не нужны учетные записи в системе)? Ведь судя по ответам там должен быть всего один внесенный разработчиками аккаунт. Опять-таки, тут идут чуть более продвинутые измышления, и я (подумав или пообщавшись с ЗЛ) пришел к выводу, что эта информация может меняться. Да, не путем манипуляций со стороны пользователей решения, а путем прямой работы с базой данных. Но все же может — я решил, что в будущем есть вероятность, что понадобятся дополнительные учетные записи для администраторов, плюс вполне себе вероятно, что придется простыми средствами (не затрагивая код) менять логин или пароль даже этой единственной учетной записи.
б) Давайте добавим связи. Связи показывают то, как большие куски данных (сущности) между собой связаны. Для тех, у кого уже есть опыт работы с базами данных, связи понять проще. Для тех же, кто совсем не в теме, предлагаю такой упрощенный взгляд: представьте, что вся эта информация будет храниться в Excel-файле. Т. е. код системы для того, чтобы отобразить пользователям какие-то динамические данные или собрать их с них и сохранить на будущее, будет лазить в этот самый Excel-файл и брать из него информацию или добавлять/менять ее в файле. В этом Excel-файле будет несколько вкладок, и каждая вкладка как раз и будет хранить конкретные экземпляры наших сущностей данных. Т. е. одной из вкладок будет вкладка “Товары”, и там каждая строка будет представлять собой один из Товаров, существующих в системе.
Теперь вопрос: строки на каких-то из вкладок будут как-то отсылаться на другие вкладки (т. е. на другие сущности данных), чтобы показать, что информация между собой связана? Полагаю, что да:
1. Заказы связаны с Товарами, т. к. каждый Заказ содержит отсылку на те Товары, которые покупатель приобретает. На этом с явно видимыми связями мы могли бы и закончить, но я немного усложню пример:
2. Пользователя (администратора) нет необходимости связывать с чем-либо, но представим, что в процессе общения с ЗЛ мы получили такую дополнительную вводную: для истории было бы полезно хранить, кто именно из администраторов (а в будущем их может быть больше, чем один) какой товар добавил. И вот теперь, чтобы учесть это, нам нужно связать Товары с записями на вкладке Пользователи, чтобы понимать, какой Товар кем из Пользователей был добавлен.
UML позволяет нам нарисовать 4 типа связей (это не обязательно, но позволяет лучше показать их смысл — главное, чтобы ваши получатели смогли это прочитать либо вы их такому научили):
- Обобщение (Generalization) (иногда называют Наследованием). Обобщение показывает, что класс-потомок Б — это дальнейшее уточнение родителя А, т. е. потомок конкретизирует родителя, проясняет, добавляет деталей. Иными словами, наследник — это то же самое, что и родитель, но с дополнительными деталями/спецификами. Например, такая связь могла бы быть между Товаром (родитель) и Ноутбуком (конкретный вид товара, потомок).
- Две следующие связи схожи по своей сути: агрегация (aggregation) и композиция (composition). Обе связи показывают отношение «часть-целое» — включение одного элемента как компонента в другой. Если композиция или агрегация идет от А к Б, это означает, что класс А является составной частью класса Б. Т. е. направление можно читать как «входит в». Агрегация считается слабой связью, композиция — сильной. Если в случае разрушения объекта-целого класс-часть также “разрушается”, то связь — сильная (композиция). Если же не разрушается, то связь слабая (агрегация). Такая связь могла бы, например, быть между Товаром (часть) и Каталогом (целое).
- Ассоциация (Association). Ассоциация — это любое отношение между классами. Мы рассматриваем ее в последнюю очередь, потому что если между классами на ум приходит какая-то связь, но ее нельзя описать с помощью наследования, агрегации или композиции — используйте ассоциацию. В целом, вся ваша диаграмма может состоять только из ассоциаций, если не хочется ее усложнять. При этом всегда делайте ассоциации направленными и всегда их именуйте (подписывайте названием). Без этого понять, что означает ассоциация в каждом конкретном случае (учитывая ее крайне абстрактное значение) невозможно.
Давайте поставим связи, отражающие описанное выше, в нашу диаграмму. Обе эти связи будут ассоциациями, потому что другие варианты не подходят по смыслу.
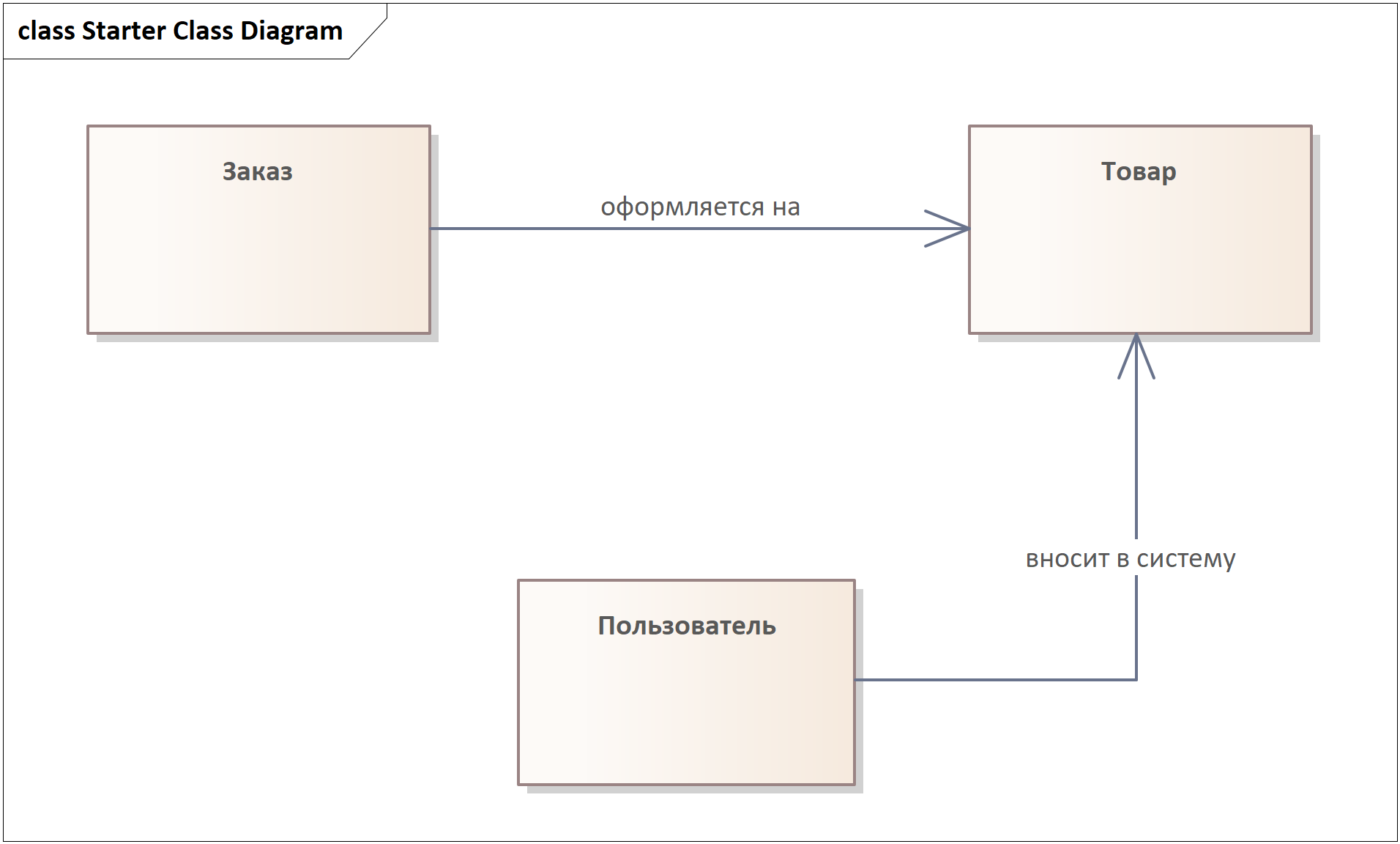
В этот момент мы можем найти недостающие требования. Например, выше мы могли сами выйти на придуманную дополнительную информацию, задав ЗЛ вопрос: “Нужно ли отслеживать кто из админов создал какой заказ?” На подобный вопрос нас может вывести собственный анализ вида “Должна ли быть связана сущность А с сущностью Б?” и “Если да, то как по смыслу?”
Теперь пришло время множественностей. Множественности — это записи на концах связей, которые показывают, какое количество объектов класса привязано к этой связи.
Читаем по направлениям связей и правильно формулируем вопросы:
1.1) На какое количество Товаров может быть оформлен 1 Заказ? Не знаем, а потому ответом от ЗЛ пусть будет, например, такое: “5, потому что это наше внутреннее ограничение”. Пытаемся сразу думать интервалом — от-до. От 1, потому что Заказ не может быть без Товаров (и сразу делаем ментальную заметку, что нам обязательно нужно будет не допускать создания пустых заказов в закладываемом поведении системы), и до 5.
1.2) Чтобы поставить цифры рядом с сущностью Заказ на той же связи: какое количество Заказов может быть оформлено на 1 Товар? Снова пытаемся думать интервалом. От 0 (не обязательно, что кто-то когда-то закажет именно данный Товар) и до неопределенной бесконечности (количество Заказов Товара на протяжении жизни Интернет-магазина ничем не ограничено).
2.1) Сколько Товаров может внести в систему 1 Пользователь (который администратор)? От 0 (каждый админ может никогда ничего не внести в систему) и до, опять-таки, неопределенной бесконечности.
2.2) Каким количеством Пользователей может быть внесен в систему 1 Товар? Странный вопрос, но для проформы нам стоило его задать. Одним, конечно.
Обновим модель:
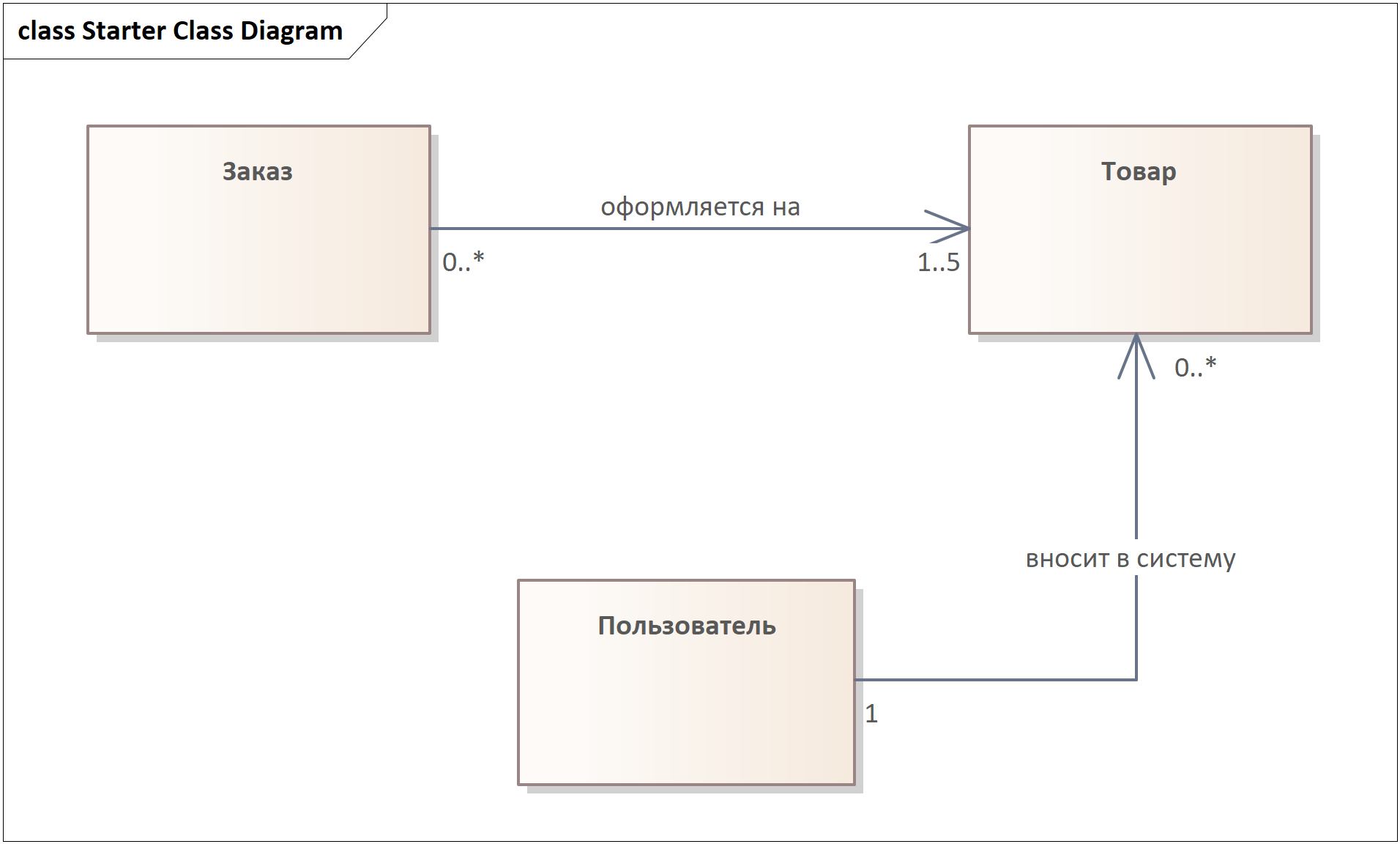
Множественности — источник крайне полезных вопросов клиенту и бизнес-правил, которые должны найти отражение в системе. В примере выше мы обнаружили внезапно, что заказ может содержать до пяти товаров. Подумали ли бы вы заранее о таком, если бы не сделали эту работу? В моей практике были примеры, когда непродумывание подобных аспектов приводило к серьёзным проектным проблемам на этапе продакшна.
Давайте теперь перейдем к атрибутам. Напомню, что в отличие от сущностей данных атрибуты — это атомарные кусочки данных, которыми характеризуется сущность данных. Т. е. из чего будут в плане информации состоять Заказы, Товары и Пользователи (их учетные записи)? Обдумав это и обсудив с ЗЛ, мы можем внести атрибуты на диаграмму, и это будет наш последний шаг по проработке этой модели. Только не задавайте ЗЛ вопросы вида “Из каких атрибутов должна состоять сущность Заказ?” Они уйдут в астрал или пошлют вас подальше с подобными вопросами. Вопросы формулируем по-человечески, например, “Когда я как покупатель просматриваю карточку товара, какую информацию я там вижу?”
Я сразу внесу атрибуты в диаграмму, после чего поясню интересные моменты:
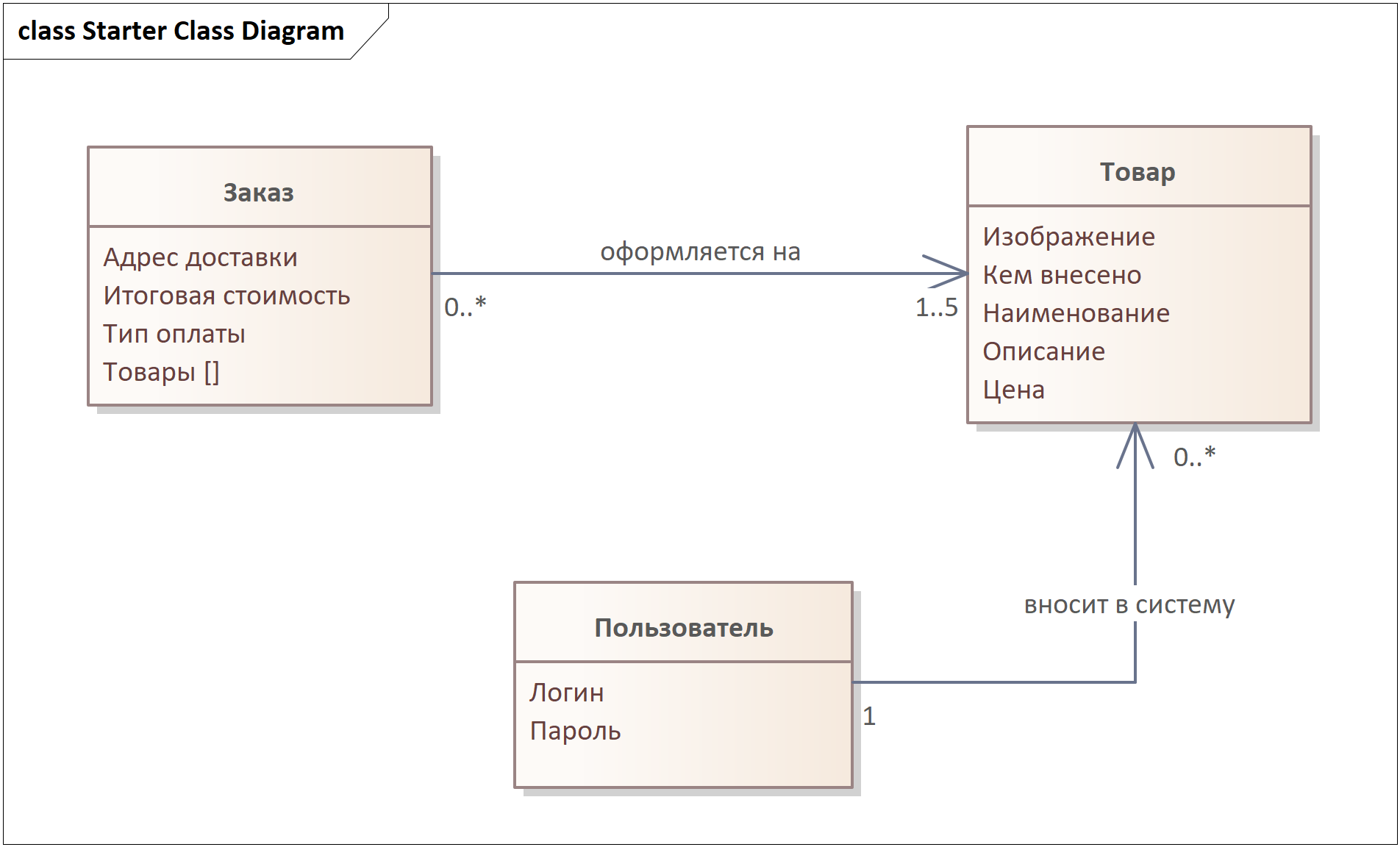
Товар:
- Кем внесено — это увязывающий атрибут, который является следствием связи “вносит в систему”. Т. е. тут у нас идет ссылка на того Пользователя, который создал данный Товар.
- У нас только Логин и Пароль. Нам не нужна пока Роль, т. к. все учетные записи в системе — это админы.
- Атрибут “Товары” содержит “[]” — так я показал, что это массив (набор) информации, а не единичное свойство, т. е. атрибут Товары будет содержать список отсылок на Товары, на которые сделан Заказ.
Не пересекаем грань: тут важно акцентировать, что именно делает эту модель логической. Как я писал выше, аналитику не стоит привязываться к способам реализации требований — он не знает заранее, что будет использоваться для физического хранения информации. Конечно, как активные участники проекта мы со временем все это узнаем, но вполне себе вероятно, что на этапе проработки этих требований это пока еще темный лес. И мы не должны принимать архитектурные или разработческие решения за экспертов, которые шарят в этом лучше нас. Например:
а) Обратите внимание, что нигде нет таких атрибутов, как ID (уникальный идентификатор). Для тех, кто привык работать с базами данных, подобное может вызвать недоумение: почему их нет? Ответ прост: с точки зрения требований ID как бизнес-параметр не нужен. Вы где-то планируете показывать его в системе пользователям или собирать с пользователей? Нет, и скорее всего ответ на то, зачем он нужен, у вас будет таков: чтобы в базе данных иметь некий уникальный идентификатор для записи, ведь они такое требуют для целей хранения. Но я напомню, что на этом этапе вы не знаете и не должны знать, будет ли в принципе база данных и будет ли выбранный подход к хранению данных требовать подобные идентификаторы. Точно так же вы не знаете, какое решение примет тот, кто это хранилище будет проектировать — вы уверены, что лучше человека, который этим на хлеб зарабатывает, предложите вариант уникальной идентификации записей для физического хранения? Я, например, не уверен (а точнее уверен, что целевые люди лучше знают), а потому и не лезу тут в область их работы.
б) В модели нет всяких промежуточных “таблиц”, которые помогут реализовать, например, связи вида “многие-ко-многим”. Мы не таблицы в базе данных тут проектируем — напомню, что мы не знаем, будет ли вообще это база данных и реляционная ли.
Во второй части мы поговорим о словаре данных и том, как его учитывать в поведенческих требованиях.
